
5 Docparser Advanced Features for Smarter Document Parsing
Organizations rely on Docparser for its flexibility and accurate data extraction, even when handling complex documents. When building a Parser,…

Automate Bank Reconciliation By Parsing Bank Statements
Bank reconciliation is essential for maintaining accurate financial records. While it can be challenging due to high transaction volumes, automation…

Bill of Lading: Definition, Types, and Importance
A bill of lading is a legal shipping document used in domestic and international trade as proof of shipment, a…

Data Entry Software Explained: From Manual to Automated
Are you looking to replace manual data entry with automated data entry software? This is the right call. Manual input…

How to Use Docparser for Invoice Automation
Accounts Payable teams often spend long hours inputting data from invoices into spreadsheets and accounting systems. This can really hurt…

Parse PDF to Text and Automate Workflows End-to-End
PDFs often lock important data in a format that systems can’t easily read or use. If you regularly process documents…

Docparser Recognized for Best Customer Support by Software Advice in 2026
We are thrilled to share some incredible news with our community! Docparser has officially been recognized for its commitment to…

Document Control Explained: Basics, Components, & Benefits
Have you ever had a last-minute panic before an audit because you couldn’t find a document or weren’t sure which…

Need a Receipt Scanner? Turn Receipts to Structured Data With Docparser
Do you have business receipts you need to input into your accounting system? Well, you don’t need to buy a…

Convert CSV to JSON in Bulk and Automate Your Processes
Do you often work with CSV and JSON files? Both formats have their advantages – the former stores table data…

Use This Free, Simple Meeting Minutes Template to Stay Organized
When attending team meetings, it’s important to take meeting minutes that are concise yet accurate. Well-written minutes keep everyone aligned…
Semi-Structured Data: What It Is And How to Extract It Easily
Semi-structured data is one of the most common types of information that businesses handle today, and yet it’s often misunderstood….

Export Bank Statements to Excel & Put Workflows On Autopilot
Getting bank statement data out of a PDF file and into a clean Excel spreadsheet is a common struggle for…

Fast and Simple PDF to Airtable Parsing Solution With Docparser
Airtable has continuously grown in popularity over the years, with over 500,000 organizations using it as of 2025. From CRM…

Convert Handwriting to Text for Smarter Workflow Automation
Handwriting recognition has made great strides in recent years thanks to technologies like OCR and LLMs. If you handle documents…

Use Our PDF Summarizer to Generate Summaries in Seconds
Do you spend too much time reading PDF documents? It’s time to turn long PDFs into concise summaries with Docparser….

Experience Smarter Content Summarization with Our New AI Feature
Since the launch of DocparserAI, our AI-powered parsing engine, we have been adding more features to help our users accomplish…

Turn Handwriting to Text Easily With Docparser
Are you tired of looking for the right tool to turn handwriting to text? Well, you’re exactly where you need…
Automate Bank Reconciliation By Parsing Bank Statements
Bank reconciliation is essential for maintaining accurate financial records. While it can be challenging due to high transaction volumes, automation…
Bill of Lading: Definition, Types, and Importance
A bill of lading is a legal shipping document used in domestic and international trade as proof of shipment, a…
Data Entry Software Explained: From Manual to Automated
Are you looking to replace manual data entry with automated data entry software? This is the right call. Manual input…
How to Use Docparser for Invoice Automation
Accounts Payable teams often spend long hours inputting data from invoices into spreadsheets and accounting systems. This can really hurt…
Parse PDF to Text and Automate Workflows End-to-End
PDFs often lock important data in a format that systems can’t easily read or use. If you regularly process documents…
Document Control Explained: Basics, Components, & Benefits
Have you ever had a last-minute panic before an audit because you couldn’t find a document or weren’t sure which…
Need a Receipt Scanner? Turn Receipts to Structured Data With Docparser
Do you have business receipts you need to input into your accounting system? Well, you don’t need to buy a…
Convert CSV to JSON in Bulk and Automate Your Processes
Do you often work with CSV and JSON files? Both formats have their advantages – the former stores table data…
Semi-Structured Data: What It Is And How to Extract It Easily
Semi-structured data is one of the most common types of information that businesses handle today, and yet it’s often misunderstood….
Export Bank Statements to Excel & Put Workflows On Autopilot
Getting bank statement data out of a PDF file and into a clean Excel spreadsheet is a common struggle for…
Fast and Simple PDF to Airtable Parsing Solution With Docparser
Airtable has continuously grown in popularity over the years, with over 500,000 organizations using it as of 2025. From CRM…
Convert Handwriting to Text for Smarter Workflow Automation
Handwriting recognition has made great strides in recent years thanks to technologies like OCR and LLMs. If you handle documents…
Use Our PDF Summarizer to Generate Summaries in Seconds
Do you spend too much time reading PDF documents? It’s time to turn long PDFs into concise summaries with Docparser….
Turn Handwriting to Text Easily With Docparser
Are you tired of looking for the right tool to turn handwriting to text? Well, you’re exactly where you need…

Automate Acord 126 Form Processing Efficiently
The Acord 126 is a widely used form in the insurance industry for collecting underwriting information. Agents, brokers, and underwriting…

A Quick Overview of Intelligent Document Automation
Moving data from documents into systems is a ubiquitous need in workplaces. How you do this decides if your workflows…

AI Resume Parser to Simplify Candidate Screening
Do you have a big batch of resumes that you need to review? Doing this manually means you may have…

Effective CRM Lead Management for Better Sales Results
Managing leads efficiently is crucial for converting them into customers. However, as you gather more and more leads, relying on…

Boost Efficiency with Bank Statement Extraction Software
Do you often find yourself overwhelmed by the amount of bank statements you need to process? This is a common…

Use Zonal OCR to Extract Data From Scanned Documents
Zonal OCR, or Zonal Optical Character Recognition, also sometimes referred to as Template OCR, is a technology used to extract…

How Alpine Industries Uses Docparser to Automate ERP Data Entry
Manual data entry is a common problem across all markets and industries. Typing information by hand into ERP systems is…

5 Warehouse Automation Tools with Great ROI
Warehouse automation is one of the biggest technological innovations in supply chain management. With its wide range of applications and…

Top Logistics Automation Systems to Implement Today
The freight industry is known for its razor-thin margins. As such, being able to deliver cost-efficient services is vital to…

Why Supply Chain Automation Is Essential to Business Growth
We live in a time of disruption, where businesses need to adapt quickly to new changes. Traditional supply chain management…

How MATERIALESDEFABRICA Uses Docparser for Invoice Organization
PDFs are an integral part of any business. Whether they’re invoices, purchase orders, bank statements, or bills of lading, businesses…

7 Back-Office Processes Automation Steps to Help Manufacturers Save
The manufacturing industry is certainly no stranger to automation. While production processes on the factory floor have seen astounding advances…

10 Retail Store Automation Examples That Save Hours Each Day!
Retail store owners and mom-and-pop shops all over the word are steadily introducing retail automation tools and software into their…

Data Extraction Overview: Use Cases and Real Examples
Using data extraction can transform your business. Although it is easy to get started with, it can take some time…

How JuicedTech Leverages Docparser With QuickBase
PDF and scanned documents are widely used to exchange information pertaining to a variety of documents including contracts, invoices, price…

ChronoScan vs. Docparser
ChronoScan Capture is a document and data capture software that works like a complete suite for document scanning and data…

Shield GEO’s Workflow Automation Using Docparser & Zapier
Shield GEO is a Global Employment Organization that helps organisations in managing their employees internationally. In particular, they assist their clients…

Docparser Solutions for Accounts Payable Automation
Accounts payable automation has become essential for today’s businesses. Especially in cases where enterprises receive and send thousands of invoices…
Zonal OCR: A Smarter Way to Extract Data from Scanned Documents
Zonal OCR, or Zonal Optical Character Recognition, also sometimes referred to as Template OCR, is a technology used to extract…

Rental Application & Agreement Parsing for Property Managers
Processing rental application forms & agreements can be an overwhelming experience for property managers. Docparser allows you to extract the…

Purchase Order Automation That Reduces Manual Work
Does your business receive tons of purchase orders and sales orders by e-mail, fax, telephone, or snail mail? No matter…
5 Docparser Advanced Features for Smarter Document Parsing
Organizations rely on Docparser for its flexibility and accurate data extraction, even when handling complex documents. When building a Parser,…
Docparser Recognized for Best Customer Support by Software Advice in 2026
We are thrilled to share some incredible news with our community! Docparser has officially been recognized for its commitment to…
Experience Smarter Content Summarization with Our New AI Feature
Since the launch of DocparserAI, our AI-powered parsing engine, we have been adding more features to help our users accomplish…

How to Choose the Right IDP Software for Your Business
In every industry, professionals spend an enormous amount of time processing documents manually. But things are changing fast. In fact,…

Extract Checkbox Data With Our New Smart Checkboxes Feature
A lot of documents, such as questionnaires, application forms, and customer surveys have areas where respondents can select their answers…

Unlock Handwriting Recognition With Our New AI-Powered Parsing Feature
The recent launch of DocparserAI has paved the way for a lot of new features, allowing users to parse documents…

The Best Software to Extract Tables from PDF
Converting scanned files to PDF (Portable Document Format) and extracting tables from PDF is necessary in today’s modern times. Often, essential business…

Free OCR PDF Scanner: Easily Convert PDFs to Editable Text
Docparser is an OCR PDF Scanner that uses OCR to extract data from PDF documents. It allows you to convert PDF to Excel files, convert PDF…

Parse Resumes Easily With Our New ResumeAI Parser Template
We’re excited to announce the release of our latest AI-powered feature: ResumeAI Parser! This new addition to DocparserAI automates the…

DocparserAI: The Future of AI Data Extraction
At Docparser, we are always seeking new ways to make data extraction simpler, faster, and more flexible. Our users typically…
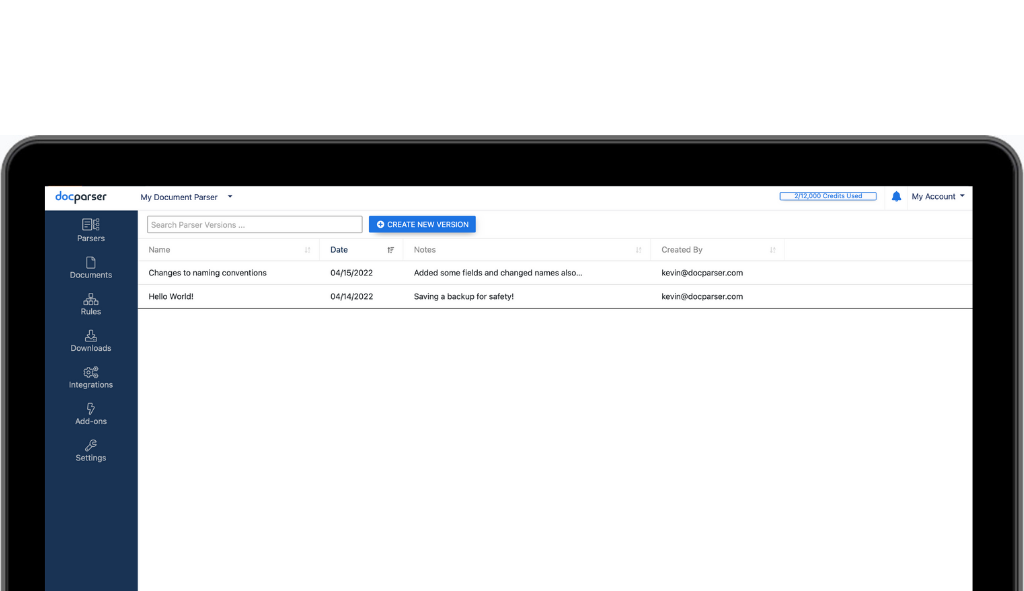
Improve Parser Management with Docparser’s Version Control
We just added an exciting new feature for managing parser logic. Parser Version Control allows Docparser customers to easily save…

Docparser: The Affordable Nanonets Alternative
Manual data entry is time-consuming, error-prone, and costly. Document parsing solutions automate this process with Optical Character Recognition (OCR). Businesses…
The Best Software to Extract Tables from PDF
Converting scanned files to PDF (Portable Document Format) and extracting tables from PDF is necessary in today’s modern times. Often, essential business…

Docparser & GDPR Compliance
Our Commitment to GDPR Compliance On May 25th 2018, the most comprehensive change to privacy legislation ever undertaken – the…

SimpleIndex vs Docparser: Is Docparser A SimpleIndex Alternative?
There are several players in the data extraction market. Many of whom not only claim to do a great job…

Kofax vs Docparser: Is Docparser A Kofax Alternative?
In the domain of data extraction from documents, Kofax is a leader. It has been in the business of process…

Ephesoft vs. Docparser: Is Docparser An Ephesoft Alternative?
When we think of data extraction, there are only a handful of companies and tools that spring up to our…

Looking for the Best FlexiCapture Alternative? Try Docparser
If you are looking for a document capture and data entry automation software on the internet, you may stumble upon…
Experience Smarter Content Summarization with Our New AI Feature
Since the launch of DocparserAI, our AI-powered parsing engine, we have been adding more features to help our users accomplish…
Extract Checkbox Data With Our New Smart Checkboxes Feature
A lot of documents, such as questionnaires, application forms, and customer surveys have areas where respondents can select their answers…
Unlock Handwriting Recognition With Our New AI-Powered Parsing Feature
The recent launch of DocparserAI has paved the way for a lot of new features, allowing users to parse documents…
Parse Resumes Easily With Our New ResumeAI Parser Template
We’re excited to announce the release of our latest AI-powered feature: ResumeAI Parser! This new addition to DocparserAI automates the…
DocparserAI: The Future of AI Data Extraction
At Docparser, we are always seeking new ways to make data extraction simpler, faster, and more flexible. Our users typically…

Parse New Document Types With Docparser: CSV, XLS, TXT, and XML
We’re excited to announce that Docparser now supports parsing of CSV, XLS, TXT, and XML documents! In addition to PDF,…
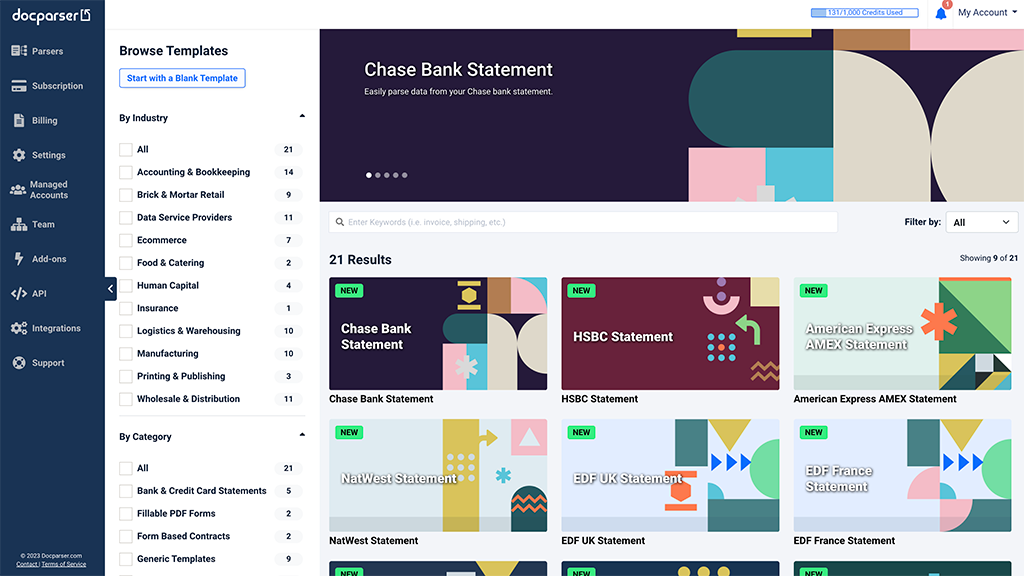
Introducing the Docparser Template Library & New Parsing Templates
We are thrilled to unveil the new Docparser template library, designed to enhance your experience and cater to your evolving…

Docparser Now Integrates With 1,000 Other Products
We know that getting your work done requires many different web tools. In fact, the average business uses between 10…

Microsoft OCR for Power Automate and Power Apps with Docparser
In need of Microsoft OCR Software? Docparser can help. OCR, or optical character recognition, converts scanned or digital text images…

Docparser and Workato Integration: Better Together
At Docparser, we recently launched our newest integration partner, Workato. Workato is “a cloud based service that lets you connect web applications…