

Zonal OCR, or Zonal Optical Character Recognition, also sometimes referred to as Template OCR, is a technology used to extract text located at a specific location inside a scanned document. This article will explain how Zonal OCR works and how it can automate data-entry workflows.
Most of today’s document and PDF scanning offer out-of-the-box Optical Character Recognition (OCR) capabilities that convert your scanned images (JPG, PNG, or TIFF files) into searchable and editable PDF documents. In some cases, however, a simple OCR system is not enough, and you need to level up your game. For example, if you are not interested in the whole text of a document but instead want to pull certain text elements located at specific positions.
The situations above are when a technology called “Zonal OCR” (also referred to as Template OCR) comes into play. Zonal OCR extracts only the essential data fields from a scanned document and stores the extracted values in a structured database. One widespread use case for Zonal OCR is to convert PDF to Excel or Automated Invoice Processing.
Use Zonal OCR to Extract Data Fields From Scanned Documents
Convert your scanned images into searchable PDF documents!
Try Docparser for free. No credit card required.
How does Zonal OCR software work?
First, let’s talk a bit about what the term means. You probably already read about OCR and how it converts scanned documents into searchable and editable documents. But having the whole text of the document accessible is only the first step.
Zonal or Template OCR goes one step further. Instead of only converting your scanned images into text, a software system can be trained to understand the structure and hierarchy of your document. By defining “zones,” it is possible to teach a zone-based OCR system to distinguish specific data fields from each other.
Let’s imagine your business receives hundreds of purchase orders or sales orders every week. Thanks to a consistent layout, it’s easy to teach a Zonal OCR system where specific data fields can be found. In addition, more advanced procedures like Docparser can apply PDF data extractions for various layouts, for example, in the case of invoice OCR processing.
What is Zonal OCR?
To sum it up: Zonal OCR is a particular type of Optical Character Recognition that extracts only specific text data fields from a document. The extraction is based on “zones” defined by the user before scanning.
Training your software
Training a Zonal OCR system means defining where all data fields can be found inside a document. This process needs to be done only once, and the locations (zones) of the data fields are then saved in a template.
Once you train your system correctly, use the zone templates for scanning further documents. And this is where Zonal OCR shines.
Once the system is adequately trained, big batches of documents with the same layout can be processed in a snap. Need to extract client names and reference numbers from hundreds of quotes, purchase orders, or sales orders? No problem at all. Once you set up your master template, all you need to do is feed more documents to the system.
Where does Zonal OCR tend to fail?
Most Zonal OCR systems are purely location-based. The advantage of such systems is that the setup is straightforward. As mentioned above, the user only needs to draw a rectangle (zone) around a specific area, and the layout is done.
The above covers only a subset of cases. Extracting data from semi-structured documents is a bit more complex. To give you a better picture, let’s look at some examples. A simple Zonal OCR system cannot handle the following cases:
- Extracting compound data fields (e.g., First + Last Name, Postal Address, …)
- Repeating data fields (e.g., Multiple product numbers, …)
- Table data
- Data fields with variable positions (e.g., Invoice totals, ..)
This is why Docparser offers a powerful set of features that goes beyond the capabilities of a classic Zonal OCR system. By providing sophisticated tools, Docparser compensates perfectly for the shortcomings of traditional methods.
What is Full OCR versus Zonal OCR?

Full OCR is another type of optical character recognition. First, software, like Docparser, reads the entire document. Then, it places a text layer on top of the PDF document. The text layer allows the searching of the full content of the document.
Full OCR is best for reports, or contracts, or any document where essential words and phrases can be searched inside the document management system.
Zonal OCR creates zones in documents and sets specific margins for entire pages. The data is extracted from these specified areas, and anything cropped out is left out. Any characters partially entered in zonal fields can’t be read.
Creating these zones or “smart zones” optimizes data extraction, accuracy and allows the user to set formatting rules for advanced document processing.
How can Docparser help?
Setting up a zonal or template OCR system is straightforward in most cases. As the data extraction is based on the location inside the document, most solutions offer a visual “zone definition” process.
For example, the screenshot below shows the setup process of Docparser. All the user must do is draw a square around the area where the data field is located.
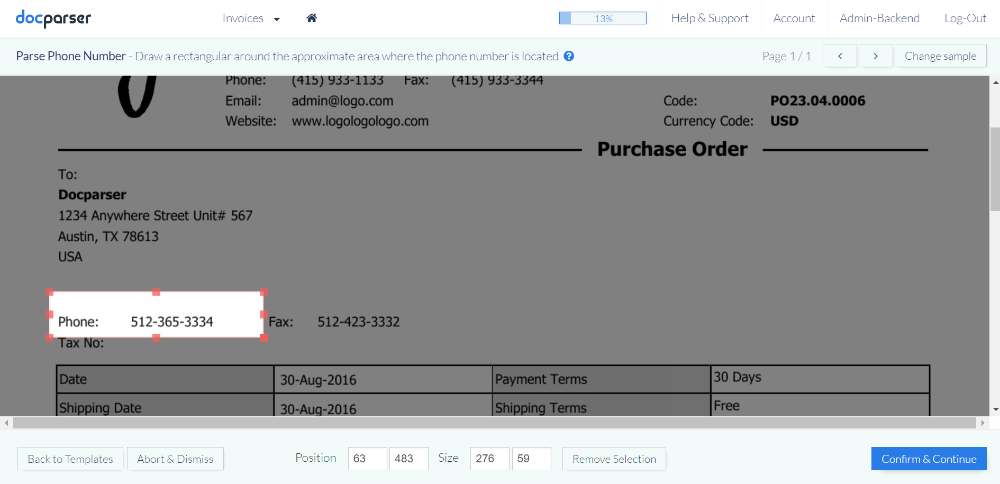
This process is repeated for each data field that the user wants to extract. In a typical scenario, the user needs to define a handful of zones, resulting in the equivalent number of extracted data fields.
Use Zonal OCR to Extract Data Fields
Convert your scanned images into searchable PDF documents!
Try Docparser for free. No credit card required.
Frequently Asked Questions (FAQs)
What are some common uses of Docparser?
We’re glad you asked our favorite question to answer. Docparser extracts data from PDFs. There are many uses, but some cases work better than others.
Docparser is best for batches of documents with similar layouts and structures. It’s best if you limit your document layouts to 1-100.
Standard document types include:
- Form-Based Contracts
- HR & Admin Documents
- Product Catalogues & Price Lists
- Bank Statements
- Fillable PDF Forms
- Accounts Payable & Invoice Processing and Automation
- Purchase & Sales Orders
- Shipping & Delivery Orders
- Various other transactional business documents
Do you offer webhooks and cloud integrations?
Webhooks and cloud integrations automatically import documents. Use webhooks and cloud integrations to import your files from a cloud storage provider, copy the parsed data to a Google Spreadsheet, database, CRM, or API.
We allow various integrations. For starters, we allow direct integrations with third parties. These are easy to set up. For example, we can automatically import your documents to the application you want or send the parsed data to the app you connected.
These include:
Integration platforms. These allow you to send your parsed data to dozens of applications. You can also import your document from different sources. Automating your data flow was never easier!
We recommend the following:
Webhooks are a form of cloud integration targeted towards developers. Webhooks are custom HTTP requests triggered each time a new document is parsed. The request is sent to an HTTP endpoint that can be defined in the format of your choice. Webhooks are triggered after we parse your document. We offer simple webhooks which let you define a target URL or advanced webhooks, giving you complete control over the HTTP request. Find out more here.
Can I cancel my account anytime?
Yes, you can cancel your account at any time. You can also upgrade or downgrade your paid subscriptions too. When you cancel, your subscription is automatically terminated, and there are no additional payments required.
Cancel your subscription on our Subscription Plan page. Even though you’ve cancelled your subscription, we don’t close your account so that you can have access to your parsed data. Your account can also be entirely deleted from our system if you’d like.
How long do you store my data?
For as long as you specify. We store the original files and the parsed data for one month. After this, we destroy the data associated with the actual file and parsed data.
You can set a data retention timeline value between 0-120 days. Zero days of retention means your data is deleted immediately. However, in case of a Webhook error, we keep the data for one week for debugging.
Can I pause my subscription?
Yes. You can pause your subscription at any time for either 3- or 6- month intervals. When you break, unused credits will be lost. Parsing your documents is also queued until the account is reactivated again, either after the pause or if you decide to come back sooner than anticipated.
Are there options for downloading parsed data?
Yes. Docparser offers two ways to download and export parsed data.
- Download as one single document.
- Download as multiple documents.
What languages does the OCR engine support?
We support a variety of languages. For text-based PDFs, we pull the text directly from the file. Please view our list of languages here.
In conclusion, Zonal OCR automates tedious processes of indexing fields. You can set up batches in Docparser to define, read, convert, and automatically populate fields within the specified zones. This reduces the amount of manual labor needed in the extraction process.
Zonal OCR helps you capture relevant documents from various file formats. You can also quickly shift all your business documents to paperless processing, making data accessible, searchable, and editable.
Use Zonal OCR to Extract Data Fields
Convert your scanned images into searchable PDF documents!
Try Docparser for free. No credit card required.


