Create your own PDF to JSON converter with Docparser
Getting started with Docparser is easy. Once you have created your first document parser, uploading a couple of PDF sample files is the next step. The samples act as “blueprint” layouts for additional PDFs to come. The idea is to set rules for data extraction for a particular document layout and simply feed more PDFs with the same layout through our parser later on.
Next to extracting simple data fields in fixed positions (e.g., Dates or Tracking Numbers), Docparser also lets you remove table rows and complex data structures from variable parts inside the document.
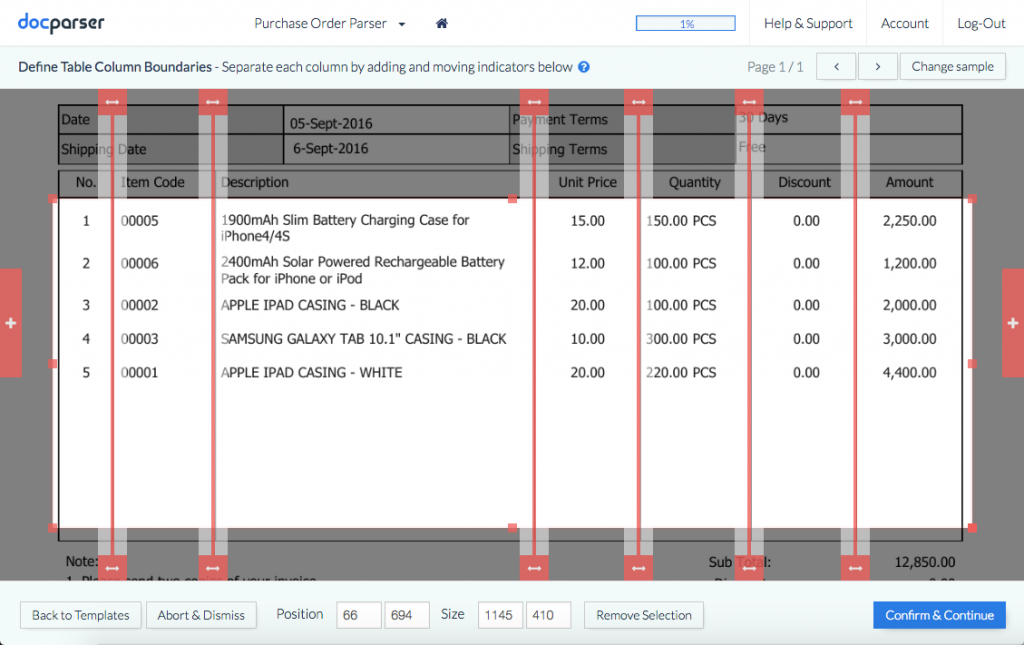
There will be times that you need to handle various PDF layouts that are structured differently, for example, if you want to extract data from PDF purchase orders provided by different trading partners. In this case, you simply create one document parser for each PDF page layout. Each document parser is then designed to batch-process many files of the same type.
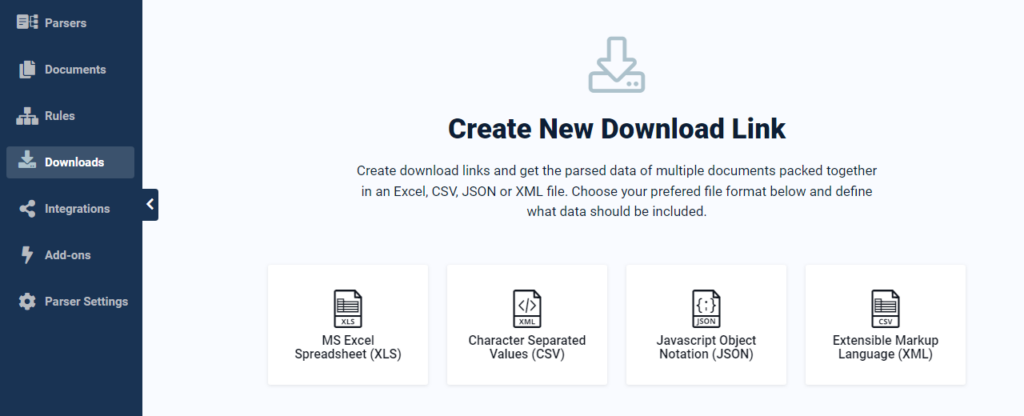
Download your converted PDF documents in JSON format
To obtain the data in JSON, you simply select the “Download Links” tab from the App interface and choose JSON as the output. You can either download the JSON data of one single PDF document or group the data of several papers together in one single file.