

What is an OCR scanner?
Optical Character Recognition (OCR) is a technology that allows you to extract data from scanned documents resulting in a text which you can then edit, update, or aggregate with other tools for data analysis and a range of other uses.
Optical Character Recognition (OCR), is essentially the conversion of scanned images with text, be it typed, in print, or written by hand, into … well … text. Typically you see OCR used in extracting text information from photos, passports, and scanned documents. OCR is often used for “digitizing” recognized text, so it can be utilized later, edited, searched, aggregated for analysis, etc.
There are often many steps to OCR
Pre-processing happens to improve the possibility of having the text recognized in the process. De-skewing is one of the most used techniques, and layout analysis to target zones of the PDF is also important to consider when extracting text with a high degree of OCR accuracy. Additionally converting grey-scale and color to black and white allows the process to focus on just 2 options (Binarization), and increases the opportunity for successful extraction of the text, from the source.
Try Our OCR PDF Scanner for FREE
If you have PDFs with text, you need OCR data extraction from PDF documents, a subscription with Docparser leaves you in the driver seat.
Whether you are working to extract information from scanned PDF invoices, purchase orders, or looking to automate the receipt of payroll PDF’s for your bookkeeper, we’ve got you covered. We use the best OCR software available that currently supports 46 languages. An example of Japanese and English scanned PDF, with before and after parsing shown below:
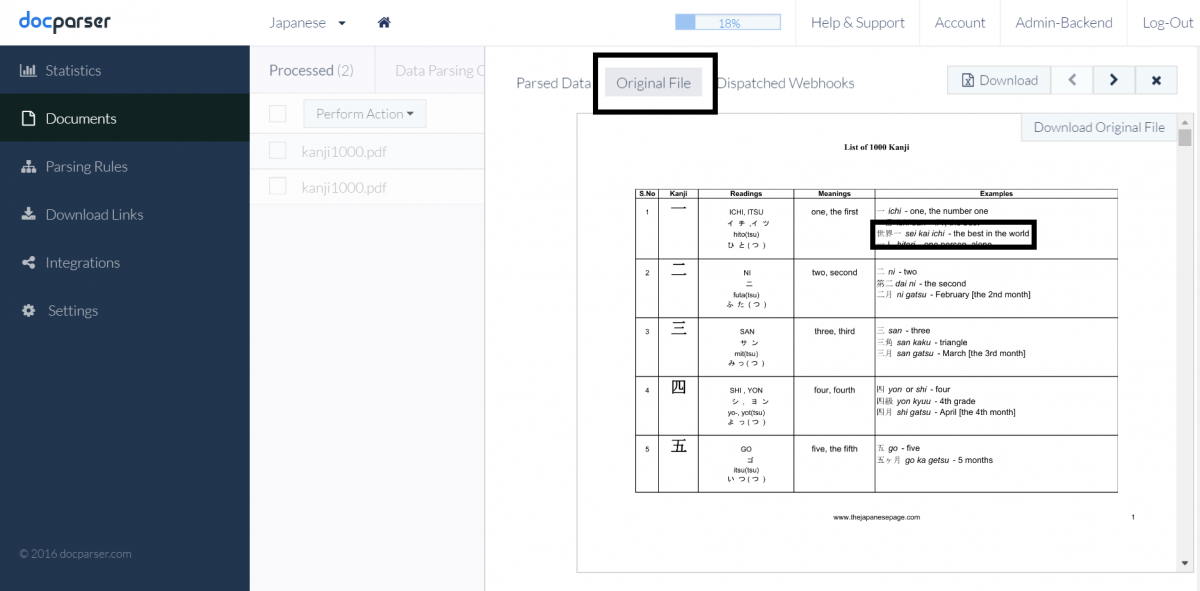
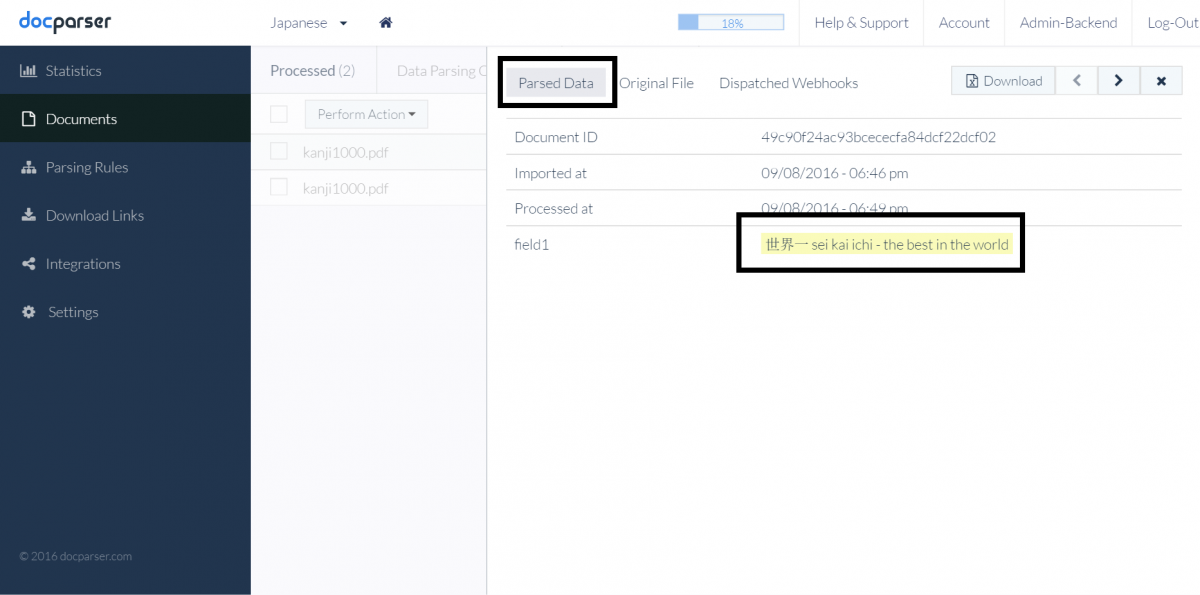
Current languages supported with our PDF OCR:
| Languages Supported | Languages Supported |
| English | Indonesian |
| Afrikaans | Italian |
| Albanian | Japanese |
| Basque | Korean |
| Brazilian (Portuguese) | Latin |
| Bulgarian | Latvian |
| Byelorussian | Lithuanian |
| Catalan | Macedonian |
| Chinese Simplified | Malay |
| Chinese Traditional | Moldavian |
| Croatian | Norwegian |
| Czech | Polish |
| Danish | Portuguese |
| Dutch | Romanian |
| Esperanto | Russian |
| Estonian | Serbian |
| Finnish | Slovak |
| French | Slovenian |
| Galician | Spanish |
| German | Swedish |
| Greek | Tagalog |
| Hungarian | Turkish |
| Icelandic | Ukrainian |


