



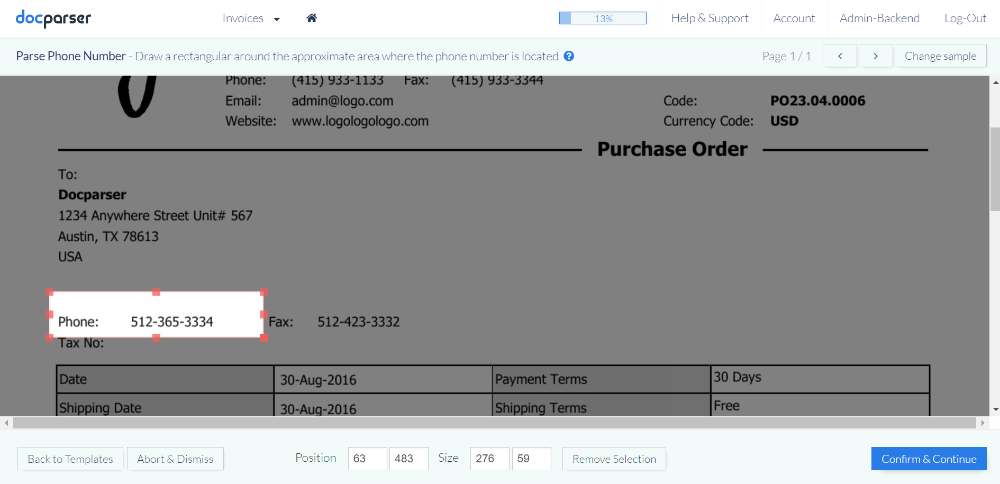
Create a managed account
Go to the list of managed accounts and click on “Create Managed Account” in the top right corner. In the box that pops up, enter the following details:
- First name
- Company name
- Email address
- Password
- Who manages the billing (this can be you)
Click on “Create Account” and you’re done. After that, you can share the login credentials with the person who is meant to use that account. They will be able to use Docparser like any normal account.
Note that the user of the managed account won’t receive an automated welcome email or anything of the sort. That said, they will see on their dashboard a notification saying that they are using a managed sub-account of your master account.
As the master account user, when you click on the name of a managed account, you can access the following information:
- Usage data
- Invoices
- The account API key of that managed account
Lastly, you can delete any of your managed accounts anytime.
Log in to a managed account
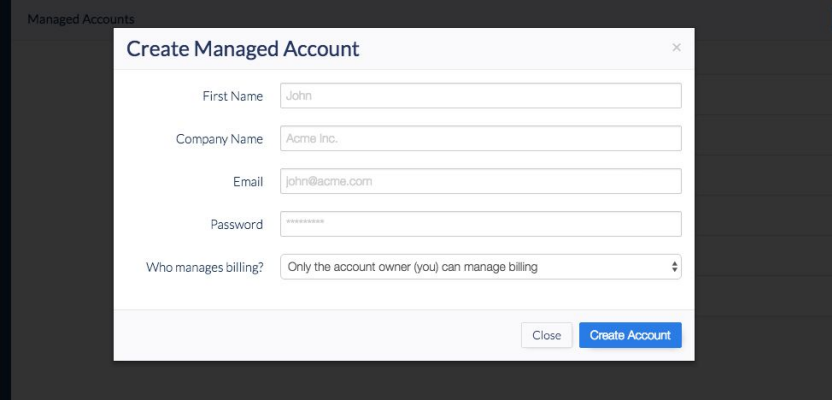
As the master account owner, you can log in to any of your managed accounts. To do that, simply go to the list of managed accounts, hover over the account you want, and click on the ‘Log-In’ blue button.
You can change the login credentials of a managed account at any time, including the account name, email address, and password. Similarly, a user can request a new password by clicking on the “forget password” procedure on their login screen.
Manage the billing of your managed accounts
As I said above, managed accounts are billed independently of the master account.
You can upgrade a managed account to a paid subscription in two ways:
- Directly through the managed accounts section in your master account
- By following the normal in-app purchase flow when logged in to the account
If you have the credit card details that are meant to be used for managed accounts, then purchasing the subscription for every managed account through your master account is the easiest and fastest option. In this case, users don’t receive emails with billing information.
In case these credit card details are not available to you, the account user can purchase the subscription on their own. They will then receive billing-related emails.
Note that you can upgrade and downgrade a managed account’s subscription anytime to match the user’s credit needs.
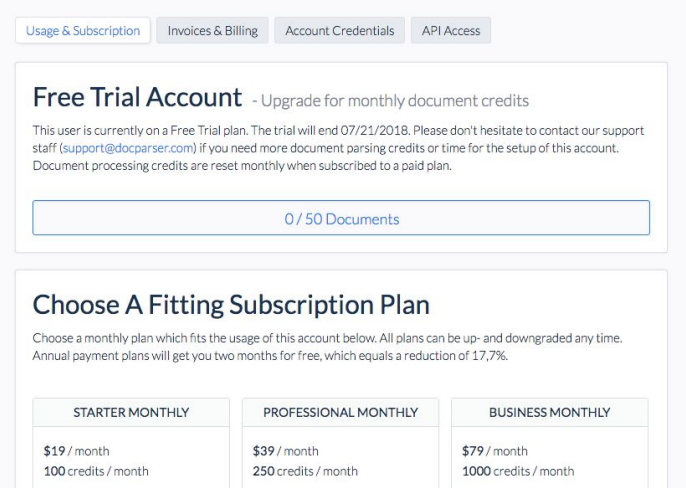
As shown in the screenshot above, you can choose between three subscription plans:
- Starter: $19/month – 100 credits/month
- Professional: $39/month – 250 credits/month
- Business: $79/month – 1000 credits/month
Copy Document Parsers between accounts
As the master account owner, you can freely copy a Document Parser from one managed account to another. Naturally, this includes all Parsing Rules, settings, and integrations.
Copying a Parser from one account to another can be very helpful for:
- Building and testing a Document Parser before sharing it with a user
- Building a library of Document Parsers that you can add to new accounts whenever needed
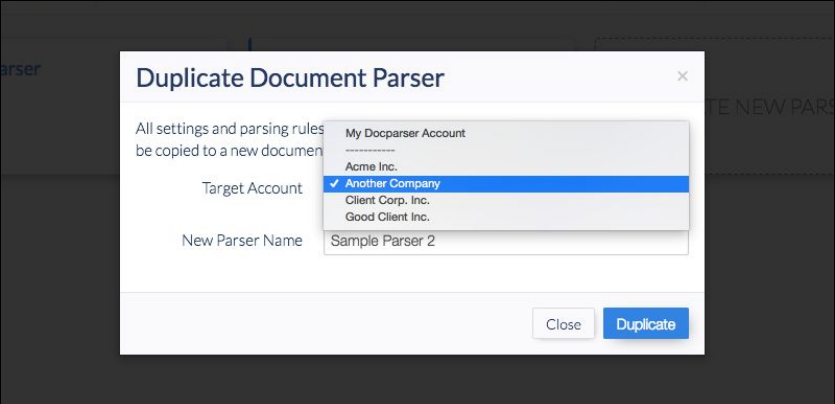
To copy a Document Parser, log in to the account where it is located and go to the list of parsers associated with that account. Click on ‘Duplicate’ and choose the ‘Target Account’ where you want to copy the Parser. You can rename it if you want.
Frequently Asked Questions
Is the managed accounts feature available in all plans?
The managed accounts feature is available starting from the Professional Plan. You can request this feature even if you are on a Free Trial plan.
Learn more about Docparser’s pricing here.
Do I need to pay an additional subscription for my managed accounts?
Yes, you will need to pay a subscription for each managed account you create. That being said, managed accounts will cost you less than if you were to create separate accounts.
What happens if a user runs out of parsing credits?
Docparser users use parsing credits to parse data from documents. When a user runs out of parsing credits, imported documents are queued up for parsing until new credits are available. You can easily purchase new credits when needed or enable automatic credit replenishment.

In Conclusion
And there you go! Now you have a clear idea of how Docparser’s managed accounts feature works and when it makes sense to use it. Whether you want to have different people within your organization who can use Docparser, or you want to have users outside your organization – like a client, the managed accounts feature lets you create and manage multiple sub-accounts from your main account.
If you have any questions about this feature or anything about Docparser, please let us know in a comment below and we’ll be happy to answer them.


