

How to Extract PDF to Oracle Using Docparser
Docparser is a no-code document parser used by businesses and organizations to extract data from documents—most notably PDFs—and send it to their systems. By using Docparser, you will automate data entry, prevent human error, and streamline your document-based workflows.
To extract PDF to Oracle with Docparser, follow these steps:
1. Create a Parser
To get started, sign up for a free Docparser account. Once you do, Docparser will take you to the Template Library page where you can find templates for different use cases.
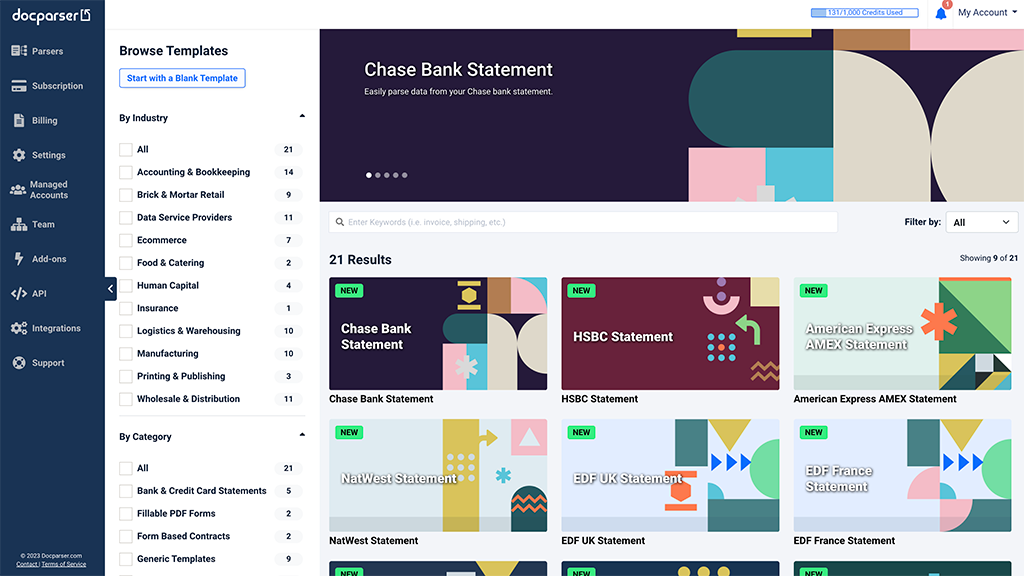
Choose one of the categories listed if it matches your document. Otherwise, you can create a blank template by clicking on ‘Start with a Blank Template’. After that, type a name for your Parser.
2. Upload a sample PDF
Next, you need to upload at least one sample PDF to Docparser. You can drag and drop your file, upload it from your local disk, send it by email, or use our REST API.
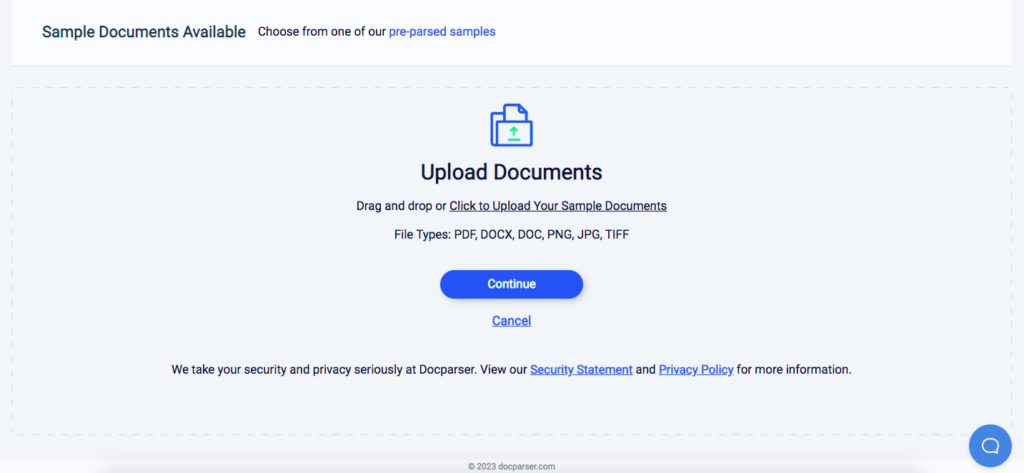
After your PDF is uploaded, click on ‘Continue’ to move to the following step.
3. Create parsing rules
To extract a data field, you need to create a parsing rule that can identify it within your document. So you are going to build a set of parsing rules for all the data fields you need to extract.
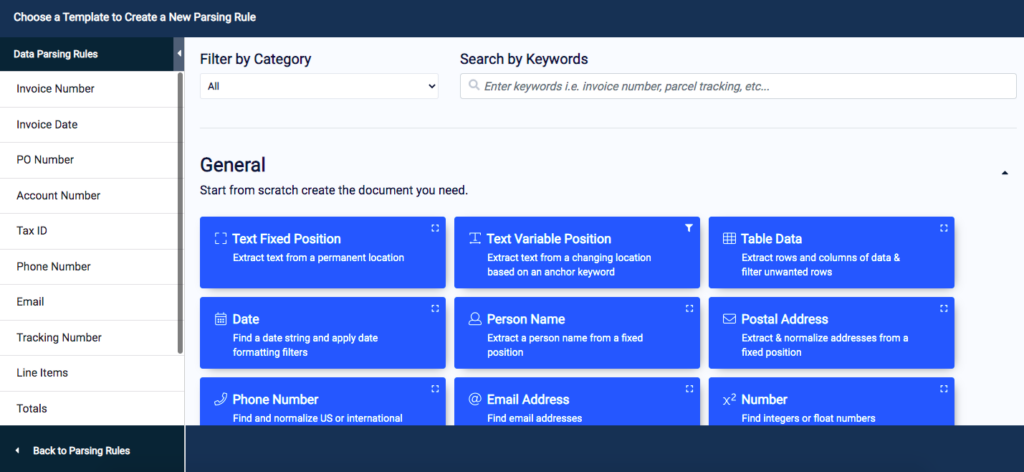
Create a rule to extract text from the PDF
Let’s start with a simple example. We have uploaded an equipment allocation report and we want to extract the reporting period. To do that, select the rule ‘Text Fixed Position’ from the options suggested, as seen on the screenshot below:
You will enter the rule editor where you can outline the data you want to extract. Use your mouse to draw a selection box around the data like this:
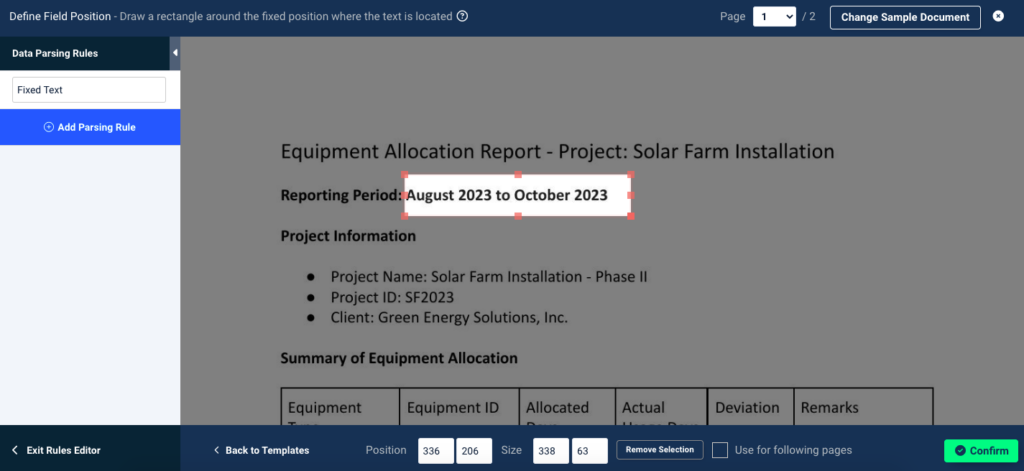
Click on ‘Confirm’ and you will see a preview of the parsed data:
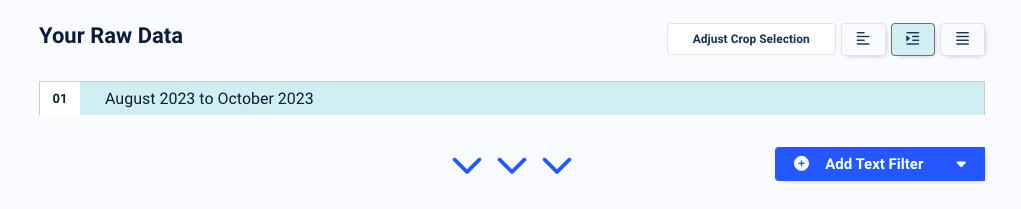
You can add a text filter to further refine the parsing results when needed. Depending on how much you want to clean up or even format the parsed data, you can chain up multiple filters until you get the perfect result you’re looking for.
For this data field, no text filter is needed. Be sure to give a name to your parsing rule by typing it in the name field to the left. In this case, we named this rule ‘Reporting Period’. After that, scroll down and click on the button ‘Save Parsing Rule’.
Okay, so now you can add another parsing rule, and so on. To add a rule, click on the blue button that says ‘Add Parsing Rule’, right below the name of this parsing rule—as seen in the screenshot before the previous one.
Create a rule to extract a table from the PDF
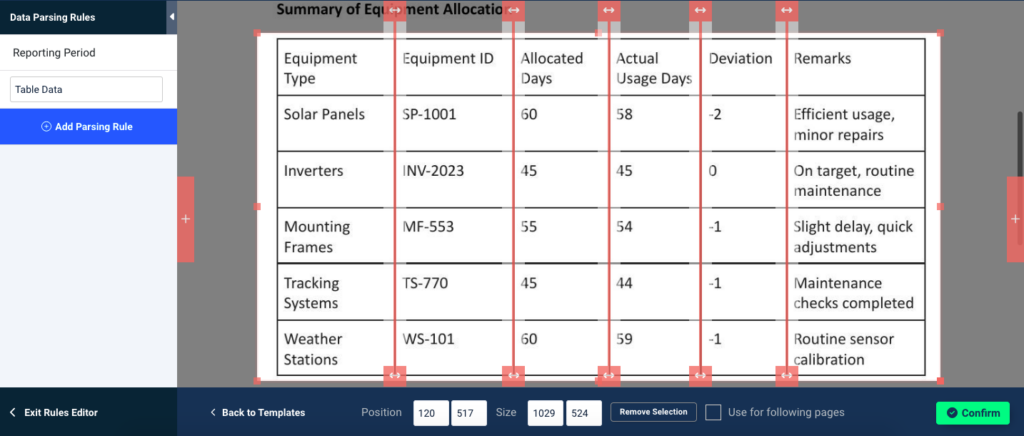
The data field we want to extract now is the summary of equipment allocation, which is a table. So select the rule ‘Table Data’.
In the parsing rule editor, you’re going to select the table in the PDF. Like with the previous rule, you have to draw a selection box with your mouse, but this time column separators are added to the mix. You can move these separators and add more by clicking on the + icons at the left and right.
Click on ‘Confirm’ and check the parsing results. Here, the second lines in the cells were parsed as separate rows, so we want to fix that. This is very easy; all it takes is one table filter.
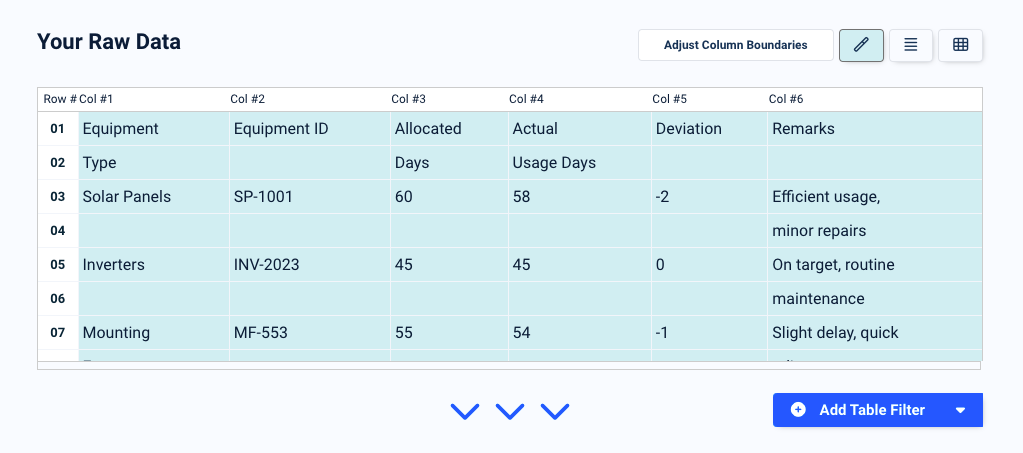
Scroll down a bit and click on the button ‘Add a Table Filter’. In the dropdown list that appears, move your cursor to ‘Add, Remove & Merge Rows’ then select the option ‘Group & Merge Rows’.
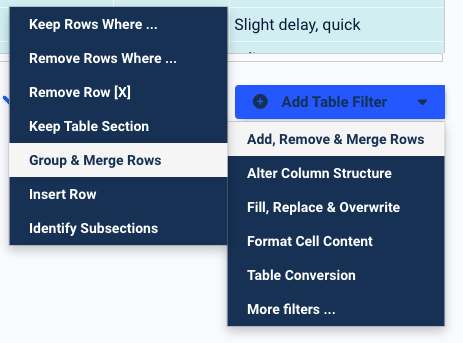
The setting for this filter will appear. In the first dropdown list, select ‘Define Rules’. Now, you want to set where a group of rows starts and ends. One easy way to do this is by merging a row with the previous one whenever the former has empty cells. This will work because in the PDF, the table has no empty cells. So select the dropdown options as shown in this screenshot:
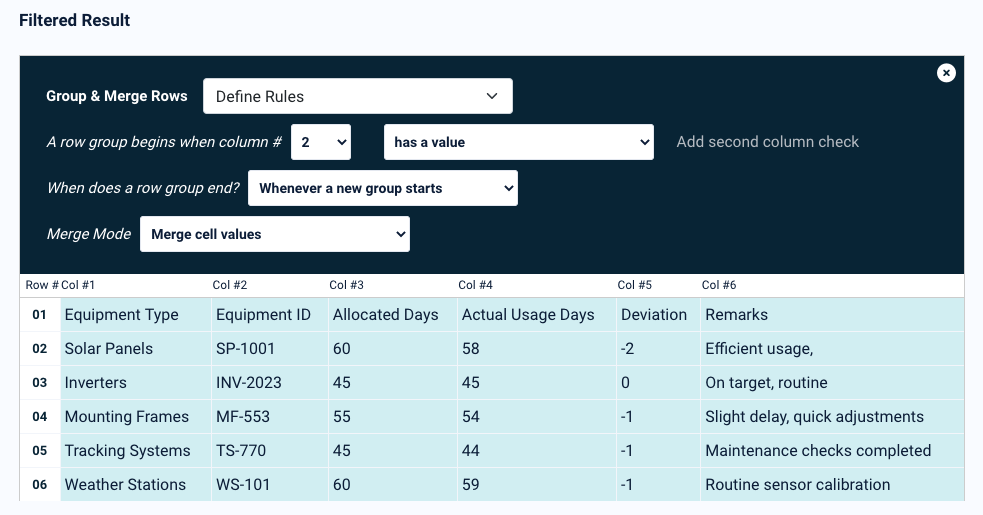
See? The parsed data is now perfectly accurate.
Don’t forget to type a descriptive name for this parsing rule. Here, we’re naming it ‘Summary of Equipment Allocation’, just like in the PDF. Save it and go back to the list of parsing rules.
Create parsing rules for the other data fields
Now you can create other parsing rules for the remaining data fields. In the mockup document we used for this guide, these data fields include:
- Project name
- Project ID
- Client name
- Remarks and additional information
- Etc.
After building a complete set of parsing rules and making sure that all the relevant data fields can be extracted accurately, you can move on to the last step.
4. Export to Oracle
Lastly, you need to set up an integration with Oracle. To do that, go to the Integrations section in the left-hand panel and click on the button ‘Add New Integration’.
Create a webhook
A webhook is an automatic transfer of data from one location to another. That transfer takes place via an HTTP request that is sent to a web address, in other words a URL endpoint. So here, you are going to create a webhook to send newly parsed data from Docparser to your Oracle database, effectively automating the process of moving data from your PDFs to Oracle.
Under the Outbound Integrations dropdown menu, scroll down to ‘Custom Integrations’ and select ‘Simple Webhook’.

In the setup screen, type a name for the webhook, choose a payload format (like JSON), and paste the target URL where you want parsed data to go.

When you’re done with the setup, click on ‘Save and Test’. Go to the URL endpoint and verify that the parsed data did arrive there without issues. That’s it!
Alternatively, you can also simply download your parsed data in the Downloads section. Go there, select the file format you want, and you will get a download link. You can then import your file into your Oracle database. Go with the option that makes most sense for you!
P.S. Want to have your Parser built for you? Request our Parsing Assistant service and our team will take care of the entire setup process in your stead.
Why Choose Docparser?
Okay, so let’s say you want to try a PDF parser. Sure enough, there are multiple tools you can find online. So it’s only fair to ask why you should choose Docparser. Well, there are several reasons why we’re confident that Docparser can be a great fit for your data extraction needs:
No coding or installing required
You don’t need to have a developer code a parser from scratch or use a parser that requires technical knowledge. Docparser is built for non-technical users, meaning that anyone in your organization can start using it within the same day to extract the data they need from documents. Furthermore, as a cloud-based application, Docparser requires no installation and is accessible from any web browser.

Built-in OCR engine
Docparser uses Optical Character Recognition, or OCR, to identify and extract data from both scanned and digital documents alike. So even if your PDF is a scanned paper document, you will get all the data fields you want in machine-readable and structured format. Furthermore, you’re not limited to the PDF format—you can also process image files (JPG, PNG, and TIFF) as well as Word documents.
Use our template library for different use cases
Docparser has a large template library that makes it even easier to build your document parser. Our library includes templates for various:
- Industries: accounting and bookkeeping, eCommerce, logistics and warehousing, etc.
- Document categories: bank statements, fillable PDF forms, invoices, etc.
These templates include pre-set parsing rules for relevant data fields. If your recurring documents don’t match the template categories, just create a blank template and build your custom parser. Plus, we can even set up your PDF parser for you with our Parsing Assistant service.
Thousands of integration options
Docparser seamlessly integrates into your data workflows in order to automate the transfer of data from PDFs to your Oracle database. By using an outbound integration as shown previously, you won’t have to import data into your database manually.
Beyond just Oracle, our integration partners—namely Zapier, Microsoft Power Automate, Workato, Make, and Claris Connect—allow users to connect their Docparser accounts to thousands of cloud applications. You can also create custom webhooks to send parsed data to any HTTP(S) endpoint in real time.
Trusted by major organizations
Hundreds of organizations use Docparser every day to process documents efficiently, including those containing sensitive information. Among them are large organizations such as Adobe, NBC Universal, and NBA. They chose Docparser because of how user-friendly, reliable, and secure it is. Security in particular is a core priority for us and we take all necessary measures to ensure data privacy and security at all times.
World-class support
Our Customer Happiness team is always available and will address your requests, troubleshoot any issues, and even build parsers for you. In fact, our quality of support is rated 9.1 on G2 (as of 2023). Customers have often praised the responsiveness of our team, its technical expertise, and ability to assist with the setup process for any kind of document.

Get Started Today
Oracle is a robust, secure, and feature-rich solution for database management. However, moving information from documents to an Oracle database can be a challenge. Instead of settling for manual data entry (not possible in many cases), or having to code a parsing tool from scratch, you can simply use a document parser to extract data locked in PDFs to your database on your own, without the need for coding.
Using a document parser to extract PDF to Oracle is far more simple and quick than developing a parser from scratch or using a data import tool with limited capabilities.


