

3 Use Cases of PDF Table Extraction
Processing invoices
Invoices always contain a table that details the goods or services purchased. That information needs to go to a spreadsheet or bookkeeping software for accounting purposes. And since invoices are most often sent in PDF format, using PDF table extraction software makes perfect sense.
PDF table extraction makes invoice processing seamless by automatically pulling key line items into a structured format. This not only saves time but also reduces the risk of costly mistakes caused by manual entry. Whether you’re managing client invoices, vendor bills, or purchase orders, automating the data extraction process can significantly improve your team’s workflow and accuracy.
“Docparser has solved a major problem of getting data out of PDF documents, this has saved us so much money and time, plus the added benefit of accuracy. We no longer have to have somebody manually importing invoices.”
— Peter K., Managing Director
Extracting bank statements
Another type of document that contains tables and needs to be processed on a regular basis is the bank statement. Bank statements are packed with important transactional data, but they’re often delivered as flat PDFs that aren’t easy to work with. Extracting tables from these documents allows you to convert static records into dynamic, filterable spreadsheets.

With PDF table extraction, you can easily isolate transaction dates, descriptions, amounts, and balances — ready to be sorted, categorized, and analyzed in tools like Excel, Google Sheets, or financial dashboards. This is especially helpful for accountants, analysts, or business owners who want a clearer view of cash flow, spending trends, and reconciliation reports without spending hours on manual formatting.
Digitizing bills of lading
Bills of lading contain essential information for logistics operations—shipment contents, container IDs, ports of origin and destination, carrier details, and more. However, these documents often come in PDF format, making it difficult to move the data to a business app.
By extracting tables from bills of lading (and other data fields like the BoL number and shipping information), you gather data that is needed for inventory systems, warehouse software, or compliance tracking. This allows you to avoid manual data entry, speed up customs documentation, and make sure that shipment information is always accurate and accessible. As a result, your team will move goods more efficiently and with fewer errors.

Why Docparser Can Be a Game-Changer for You
Use it instantly — no installs required
As we mentioned earlier, Docparser doesn’t require you to download and install it. You just sign in from your favorite web browser and start using it right away. That’s the beauty of a web-based solution: you can use it instantly from any device, anywhere. Need to process a bunch of new PDFs on the go? Simply log in to your Docparser account from your laptop.
Handle high volumes fast
Another big advantage of using Docparser is uploading multiple documents and processing them all at once. In addition to direct upload, you can send documents by email, connect a storage provider to your account, or even use a REST API to import documents. Docparser then extracts tables and other data fields based on a set of parsing rules, with processing times being generally quite fast.
Get clean, structured data every time
By customizing parsing rules to fit your specific needs, you make sure that tables are extracted and structured accurately (as long as incoming documents follow a consistent layout). A big pain point often expressed in online discussions is having to clean up data after extracting it from PDFs.
This is where Docparser shines: you can define the table’s structure by drawing the perimeter and moving (as well as adding) sliders that delineate columns.
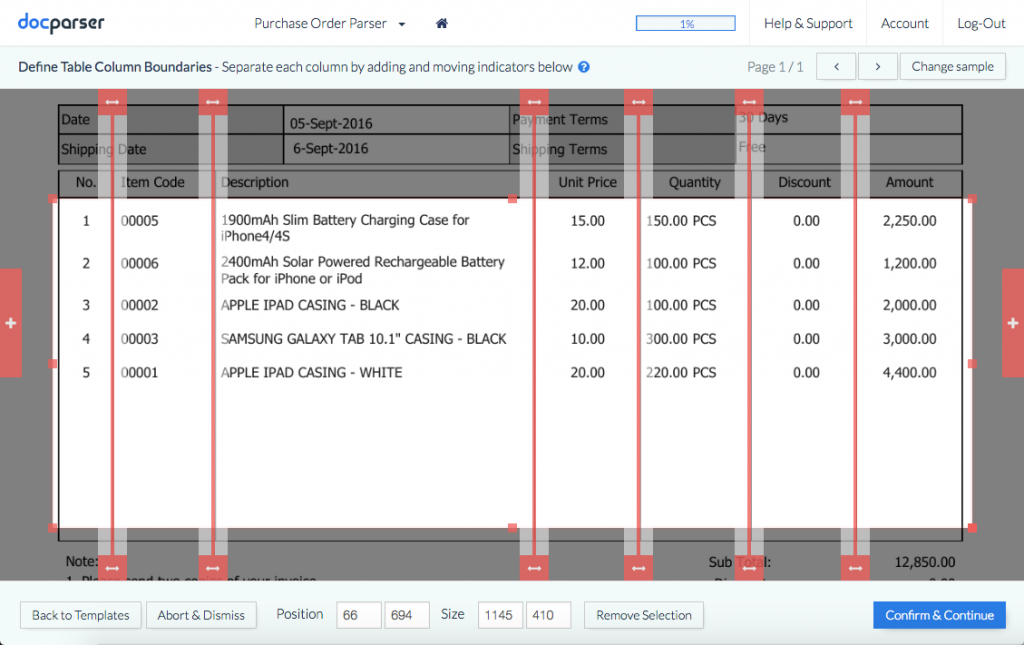
But that’s not all. You can add table filters to clean up and organize the table data. For example, you can create filters that:
- Add, remove, or merge rows.
- Filter rows based on specific terms or data types.
- Remove currency symbols ($, €, etc.) from amounts.
- Split or merge columns.
- Change capitalization.
- And more!
Automate your workflows end-to-end
Docparser doesn’t stop at data extraction; it can send your data where you need it to be. Some tools only let you download table data as a CSV or XLS file. Docparser, on the other hand, can connect to your business systems to move parsed data there.
Thanks to our integration partners (such as Zapier and Make), you can connect Docparser to thousands of apps (like Google Sheets) and APIs. This allows you to automate workflows end-to-end, from processing documents to sending data and triggering automated actions. So on top of saving valuable time, you make sure you don’t miss out on new data.
Here is one example of how a user automated a workflow using Docparser:
“I’m using Docparser to extract addresses, dates, and rows of costs and refunds from receipts. The data is processed by Zapier and forwarded to Google Sheets. This allows me to have automatically updated pivot table reports available in the Sheet. IFTTT watches the Sheet and sends a push notification to my phone when new data is available.”
— Verified user on Capterra.
Get Started Today
You don’t have to keep searching on forums for a tool that matches your use case (but doesn’t work for others). Likewise, you don’t need to write a custom data extraction tool from scratch. Just build your own PDF parser in Docparser within minutes and say goodbye to the woes of data entry. No need to install PDF data extraction software, train a model on large datasets, or use a Python library. Instead, you build parsing rules within minutes and extract tables stuck in PDFs. Then, you download your data or send it to a software app. Start with PDF table extraction and then build more parsers for your other data extraction needs. Once you experience the speed and accuracy of Docparser, data entry will never be a hurdle in your daily tasks. Sign up for a free trial and start parsing your tables with ease.


