

What is OCR?
OCR stands for Optical Character Recognition. It is a widespread technology to recognize text inside images, such as scanned documents and photos. OCR technology is used to convert virtually any kind of image containing written text (typed, handwritten, or printed) into machine-readable text data.
OCR technology became popular in the early 1990s while digitizing historical newspapers. Since then, technology has undergone several improvements. Nowadays, solutions deliver near to perfect OCR accuracy. In addition, advanced methods like Zonal OCR are used to automate complex document-based workflows.
What is OCR used for?
Popular use-cases

The most well-known use case for OCR is converting printed paper documents into machine-readable text documents. Once a scanned paper document goes through OCR processing, the text of the document can be edited with word processors like:
- Microsoft Word
- Google Docs
Before OCR technology was available, the only option to digitize printed paper documents was manually re-typing the text. Not only was this massively time-consuming, but it also came with inaccuracy and typing errors.
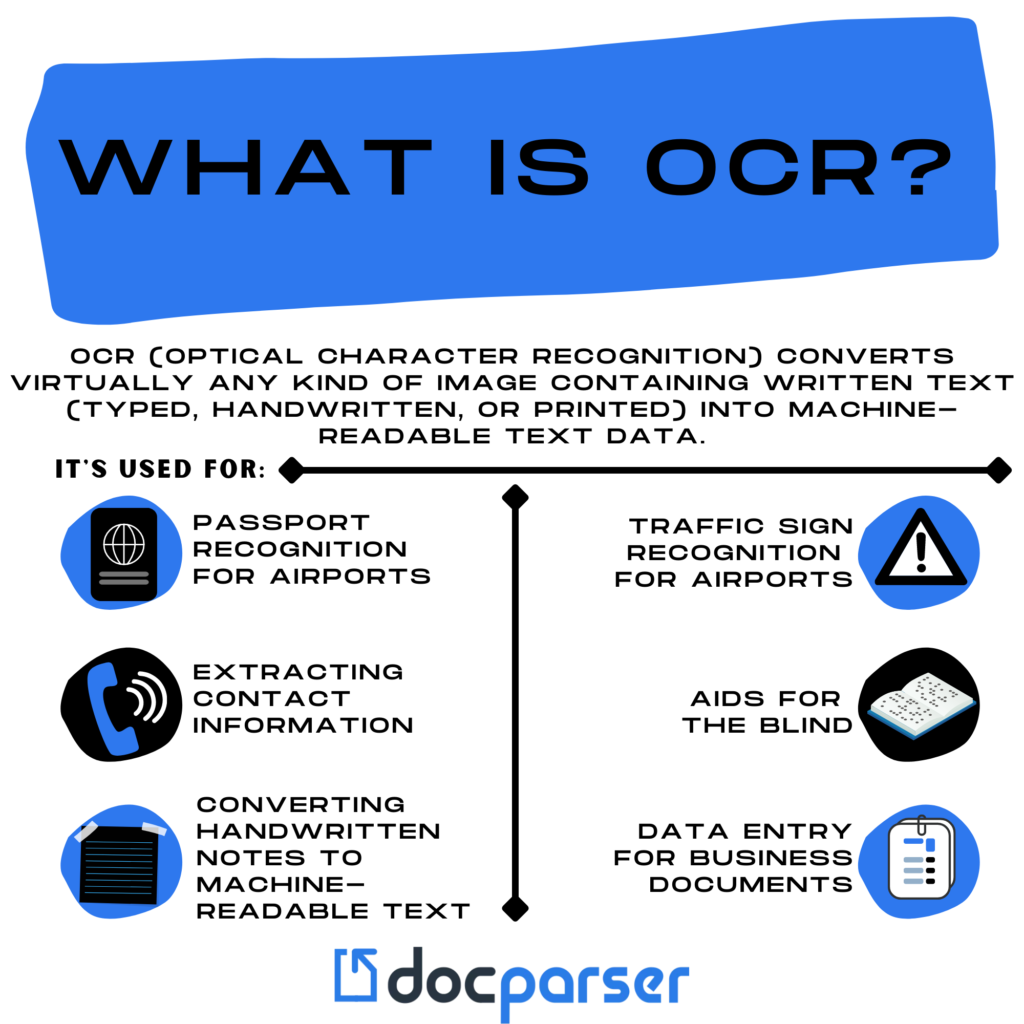
OCR is often used as a “hidden” technology, powering many well-known systems and services in our daily life. Less known, but as important, use cases for OCR technology include:
- Passport recognition for airports
- Traffic sign recognition
- Extracting contact information from documents or business cards
- Converting handwritten notes to machine-readable text
- Defeating CAPTCHA anti-bot systems
- Making electronic documents searchable like Google Books or PDFs
- Data entry for business documents (bank statements, invoices, receipts)
- Aids for the blind
OCR technology has proven immensely useful in digitizing historic newspapers and texts that have now been converted into fully searchable formats and has made accessing those earlier texts easier and faster.


