

For a more detailed explanation of the process, follow this step-by-step guide:
1. Create a parser
To get started, sign up for a free trial account. Upon creating your account, Docparser will take you to the template library, which contains pre-built templates for specific use cases. To do this, let’s try SmartAI Parser, our AI-powered template.
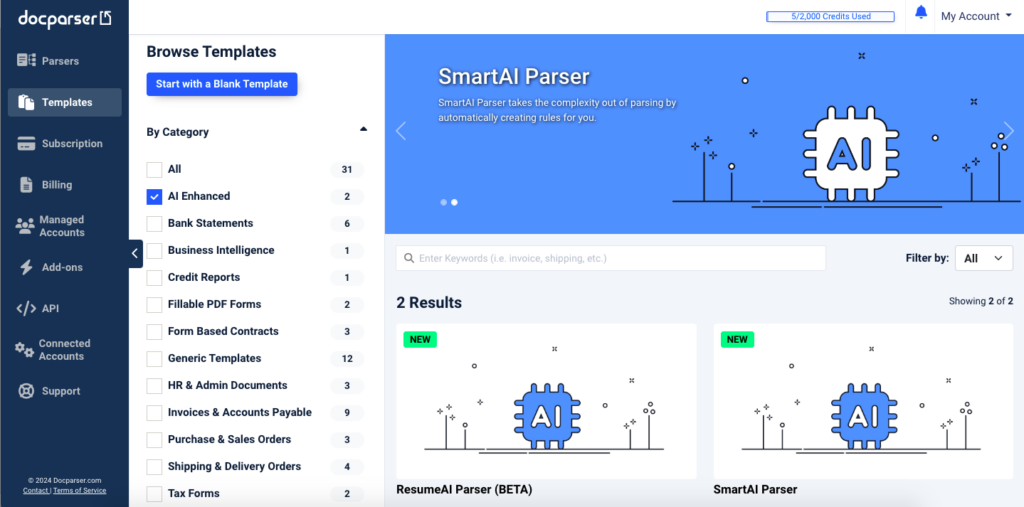
Select the SmartAI Parser template and click on ‘Use This Template’. Then, type a name for your parser.
2. Upload your image
Upload your image from your local drive or through a storage provider. For this tutorial, we want to extract text from a purchase order in JPG format. Note that you can also extract text from a PDF image, a PNG, or a TIFF image.
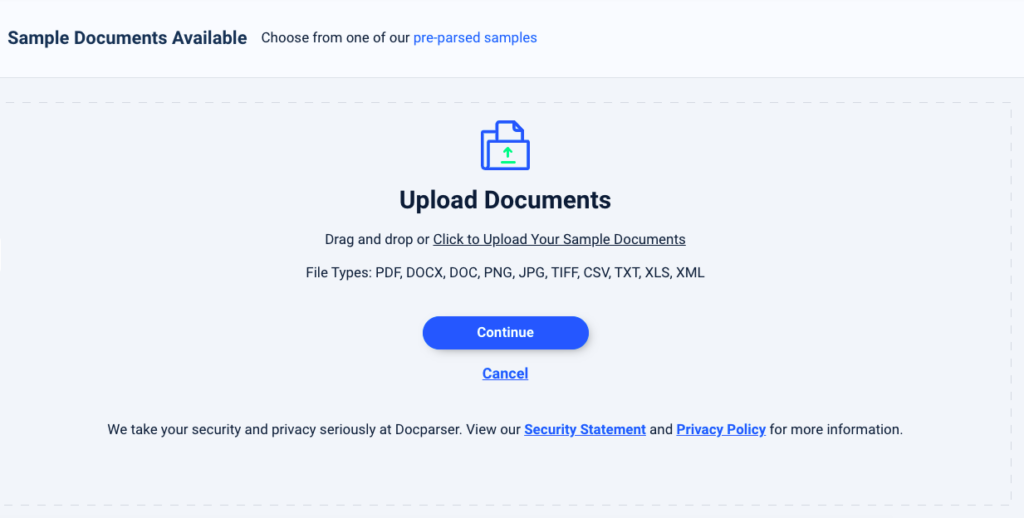
Once Docparser imports the file, click on ‘Continue’.
3. Create parsing rules
To extract text from images, you need a set of parsing rules. Each text or table field in the sample image requires a parsing rule that tells Docparser where to look for that data field in the image. You can build parsing rules manually, or simply let SmartAI Parser create them for you. Let’s take a look at the automatically created rules:
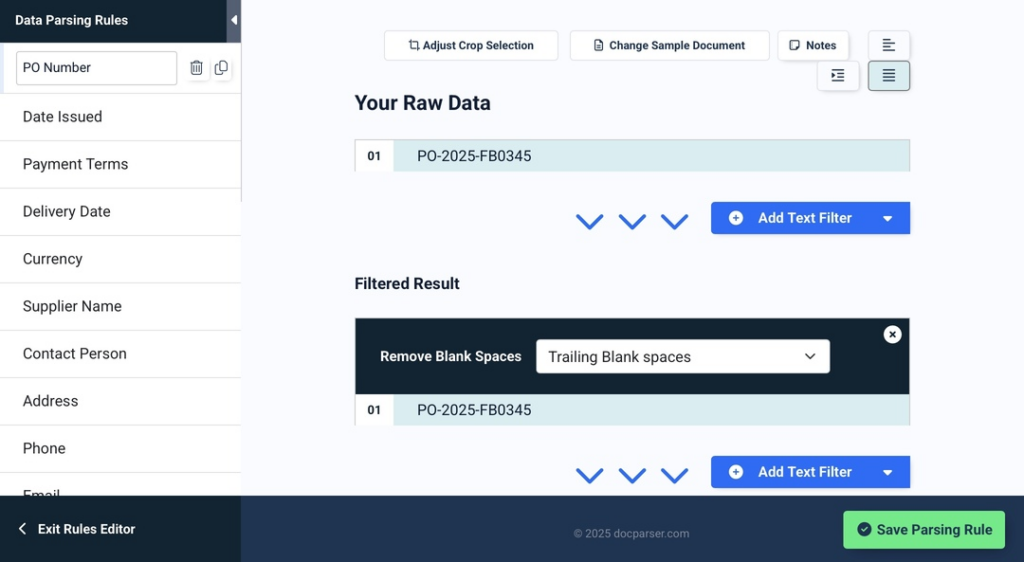
You can edit each rule to refine the parsing results. For example, you can adjust the crop selection for a given text field like this:
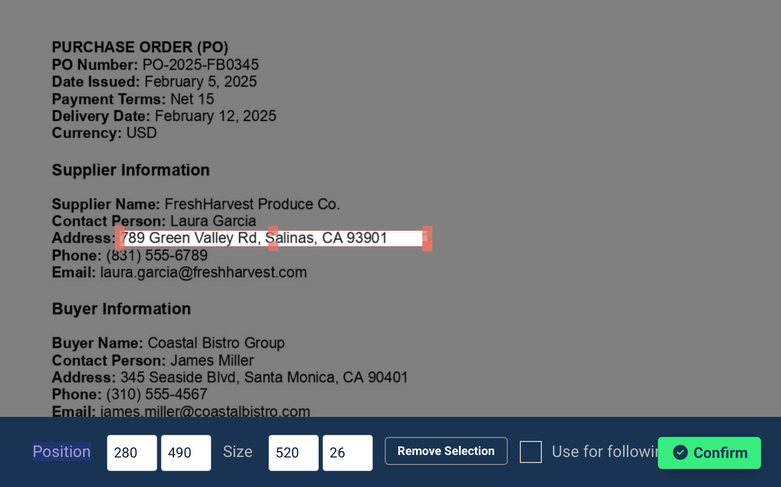
Be sure to check the parsing rules and make adjustments if needed. Note that you can rename rules, add more rules, and delete unnecessary ones.
You can see all the extracted data by clicking on your image in the Documents section.
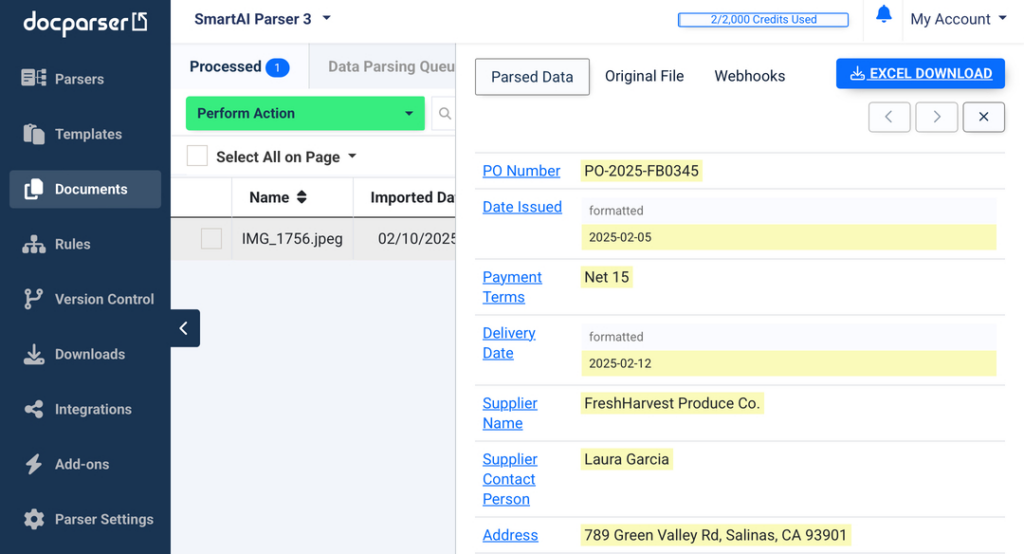
4. Send your text where you want
Lastly, you want to determine where you want parsed data to go.
You can download a file of your parsed data in XLS, CSV, JSON, or XML format. Alternatively, you can also export your data to a cloud application of your choice. For example, we can create a new purchase order in QuickBooks Online with the data from this image. You could also have a new Google document automatically created and filled with the data from a newly parsed image document. Or you could add the contact details in a business card to your CRM.
To export parsed data, simply go to the Integrations section and choose the integration you want.

Follow the simple instructions provided, which consist mostly of logging in to your preferred cloud app and mapping the parsed data with the corresponding data fields in the app. When using a third-party integration platform, like Zapier, you can even automate an entire workflow such as updating a spreadsheet with new rows or creating a new record in a bookkeeping system.
Why You Will Love Using Docparser
So now you have a good idea of how Docparser works to extract text from image files. But you might be looking at some other options to convert text from image online, trying to figure out which one is best for you. Well, allow us to explain the features and benefits that Docparser offers and which users love. We would even wager that you too will love using it once you take full advantage of its capabilities.
Powered by OCR and AI
Basic converters struggle with complex layouts, handwritten text, or poor-quality images. On the other hand, Docparser uses a powerful OCR engine, advanced pattern recognition, and anchor keywords to identify and extract data from image-based documents. But that’s not all: last year, we launched DocparserAI, our AI-powered engine that makes Docparser even more powerful, efficient, and versatile than before. By combining OCR and AI, DocparserAI can automate the rule creation process, simplify data extraction and integration, and achieve excellent data accuracy.
Customize the data extraction process
Docparser gives you the freedom to customize your parsing rules as thoroughly as you need, a feature that is absent from regular converters. Essentially, you add one or multiple filters to a given rule in order to refine the parsing results. For example, you can set up filters to:
- Remove blank spaces or empty lines
- Optimize the structure of a table
- Change the formatting of a date or phone number
- Etc.
Once you finish customizing your parsing rules, you will get accurate and consistent data points. This means you won’t be stuck fixing inaccuracies after processing documents — an issue that occurs often with other tools.
“Unlike other systems we looked at, Docparser gives us flexibility and control over how the data is being extracted. We set our parser to extract the information we need from each file and automatically connect it to a Google Spreadsheet shared by our management teams. This allows all the managers to see our current workflow in real time and make appropriate changes to schedules, inventory etc. Our turnaround time is shorter, and customers are even happier than they were before.”
— Alex, Mingo Press
Docparser supports multiple file formats
Docparser can process image files in JPG, PNG, And TIFF formats. But images are not the only type of documents supported! In fact, aside from images, you can parse documents in multiple formats, namely: Word, PDF, CSV, XLS, TXT, and XML. So you can use Docparser for a wide variety of data extraction needs, from invoices to bank statements, PDF forms, and a lot more.
Docparser supports multiple languages
In addition to English, Docparser supports Spanish, French, Italian, German, Danish, Dutch, and many other languages. To see the full list of supported languages, please visit this page.
Handwriting recognition
Another advantage of using Docparser is that you can extract handwritten information with high accuracy. If you handle documents that include handwritten notes, you’ll be happy to learn that you can extract them with as much accuracy as digital or printed text.

Recommended reading: Unlock Handwriting Recognition With Our New AI-Powered Parsing Feature
Checkbox data extraction
Do you receive documents that contain checkbox selections, like customer feedback surveys or scanned medical forms? Well, Docparser can extract checkbox data accurately too. Our Smart Checkboxes parsing feature can identify checkbox fields and provide a value (0/1, yes/no, true/false) along with a confidence score, making checkbox data extraction easy and accurate.
Recommend reading: Extract Checkbox Data With Our New Smart Checkboxes Feature
Process images in bulk
Forget about uploading documents one at a time, or struggling with daily upload limits. If you have a large number of images to process, that won’t be an issue.
You can upload multiple images at once and have them processed in a matter of minutes.
Automate entire workflows
Docparser can integrate with thousands of cloud applications. This means you can automatically send extracted data to virtually any app that you use and even automate entire workflows like:
- Create new invoices in QuickBooks Online
- Create Trello cards with data parsed from PDFs
- Upload parsed data to Google Docs as a new document
So with all these features and benefits, Docparser stands out as a comprehensive document processing solution that is user-friendly yet deeply customizable. It combines the best of OCR and AI to address most data extraction needs.
4 Use Cases of Extracting Text from Images
Digitizing physical documents
Tired of looking for paper documents on a cluttered desk? Are you concerned about losing them someday? If so, you need to digitize physical documents. After scanning them, you can process them with Docparser’s OCR capabilities to extract the data inside and have it available in digital format. Turning physical documents into digital documents makes them organized, searchable, and more secure. Whether you’re transitioning to a paperless office or need an efficient way to archive old records, Docparser helps you with the digitization process by ensuring accurate data extraction.

Bank statements
Professionals in industries like insurance and healthcare can face difficulties when processing large volumes of bank statements. Due to slow turnaround times and high error rates, automation becomes a must. In this case, using Docparser is a game-changer. You just upload multiple bank statements and extract key information like dates, account numbers, transaction details, and amounts within minutes. You can then reclaim your time and focus on more important tasks such as finding discrepancies, financial analysis, detecting fraud, auditing, and many more.
Students notes
Students often struggle with lecture notes, study notes, and other written materials that pile up and get messy. They need to have them in a digital format so they can keep them organized and searchable. Instead of spending an awful amount of time typing notes by hand, Docparser makes it easy for students to turn them into editable, searchable text. That way, they have a lot more time for studying and working on projects.
Business cards
Networking events, conferences, and client meetings often leave you with a stack of business cards. Extracting contact details — names, job titles, phone numbers, email addresses, and company names — using Docparser is a breeze. Just scan the business cards and upload the images to your parser. Then you can send the extracted data to your CRM, ensuring you keep an organized lead database and follow up with leads promptly.

