

You have business documents you get in pdf format: invoices, work orders, purchase orders, and others. Sometimes data is in the pdf as a table or documents were scanned into a pdf. They hold data you need to process in your ERP or other database-driven information systems. Unfortunately, PDF documents do not come with an easy ‘PDF to database‘ function which can be used to get hold of your data.
So how can you convert these PDF documents into usable data for your database? You use Docparser, that’s how!
Docparser is a leading PDF converter with some processing muscle and a few friends to get the heavy-lifting of data intake done for you.
How to Convert PDF to Database
This post refers mainly to the MySQL database, where Docparser is the first step to building your PDF to MySQL converter. Keep in mind that Docparser has no requirements on database vendors and the presented method is also applicable for databases such as Postgres and NoSQL databases such as MongoDB.
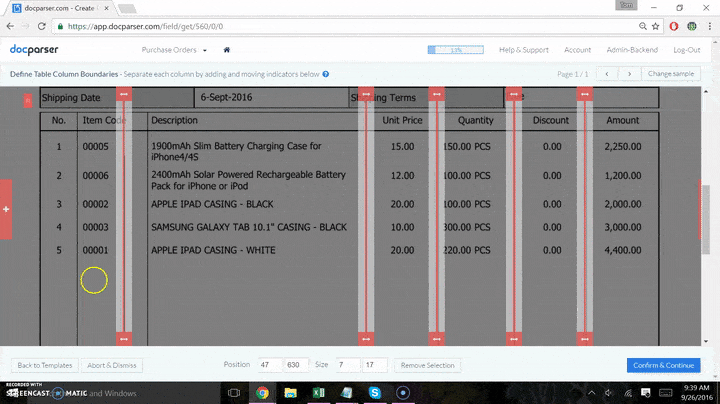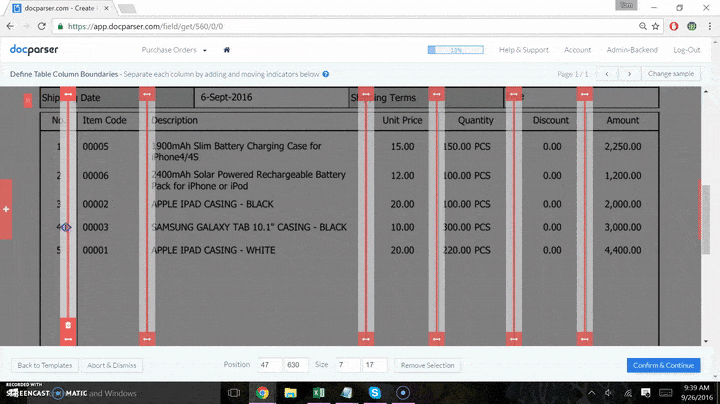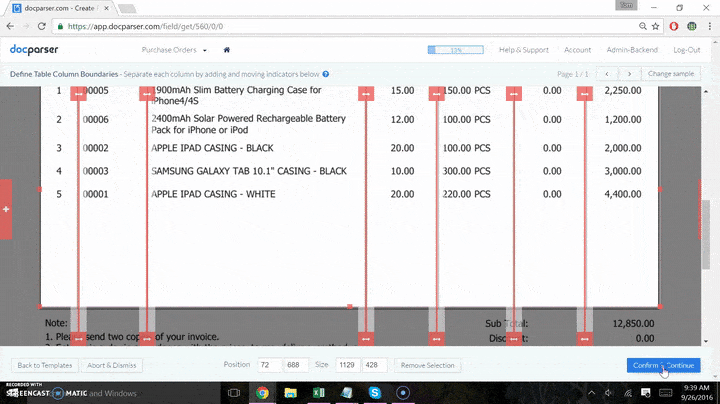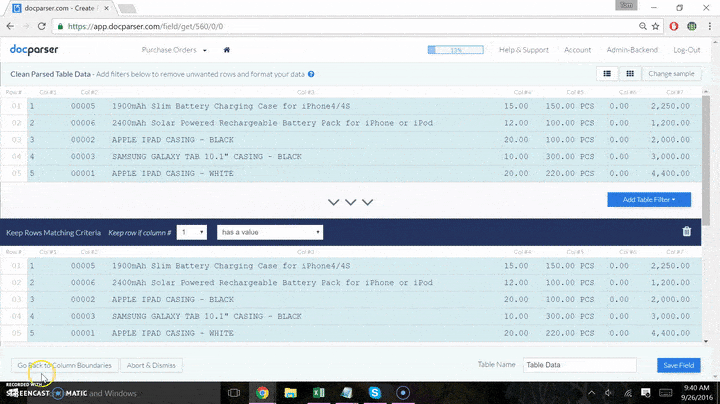
- Set up parsing rules and import your files for each type of document you want to bring in. This step is required no matter where data goes after capture. You will need Docparser to get the data out of the PDF and ready for your database.
- Determine which method you will use to move PDF data to the database of your choice:
- Download parsed data in CSV file format and manually import to your database admin interface
- Use one of our partner integration platforms to move the data from Docparser to your database. This can be through Zapier, Microsoft Flow, Claris Connect, or Workato, each allowing you to create the workflows you need.
- Develop a custom script and leverage our API to move data from Docparser to your database
Our Three Options to Convert PDF Data to MySQL, Postgres or No-SQL databases such as MongoDB
Each different type of document processed requires its own parsing rule. If you have 2 vendors using the same template for invoices, you can use the same parser for both. Clients often use a separate parser for each vendor for clarity.
The first option requires the most manual intervention but is quick to implement
For this option, you use Docparser to convert the PDF data to a CSV file which you can import via the admin interface of your database. For example, most admin interfaces for MySQL come with an upload function that you can use.
While this does require manual intervention, it is a good way to move information from PDF documents to your MySQL database. All you need to do is to build a document parser for each document type you want to extract data from.
In the next choice, we use an integration platform to automatically move the PDF data to our Database
As soon as Docparser processes the incoming file, data posts to the integration platform you have identified for that parser. The information loads to your MySQL database through the integration partner of your choice which can be Zapier, Microsoft Flow, or Workato at the moment of writing.
Each of the data integration platforms mentioned above comes with its own specialty. Zapier for example is a great fit for small and medium-sized companies, while Workato is more targeted to enterprise customers. Microsoft Flow is great if you are already using Microsoft database products such as Microsoft Access, or Microsoft SQL Server. You can find more information on each platform on the pages linked above or in our support area once you created your free account.
In the third method, we develop a custom script which leverages the Docparser API
A developer can easily build a custom PDF to database program by leveraging the Docparser API. Our API comes with a variety of functionalities including:
- Identify all defined parsers, by ID and name
- Upload documents for parsing, via HTML form or an accessible URL
- Apply a unique identifier to any document which you submit
- Receive data via a Webhook Integration to your application, a permanent download link, or by polling and fetching from your API
- Fetch data for your API in single or multiple data sets
Instead of polling our data for parsed data, you can also leverage our Advanced Webhook feature. The advantage of using webhooks is that parsed data gets sent in real-time to your custom script. Once a new document is parsed, it then sets off a trigger, eliminating polling activity and providing data to the database. This is usually complete within 1 to 3 minutes of document submission. From there, your MySQL database table populates immediately, by a timer or based on data volume levels.
If you wish to manipulate your data further after processing, you could send the parsed data to an advanced integration platform like Paragon which could run custom code you write, then place the data in your database.
Where to Start?
Some clients start with one method and build their next iteration to a different method. This is a good way to expedite your data capture while leveraging available tools and testing your process.
These are the different ways to convert a PDF to database records and Docparser can help simplify this process. The Docparser team is always here to help you get up and running as quickly as possible. Quit re-entering your data! Isn’t it time you got some automation into your data intake?
Sign up for a free account today and see how much easier your workday can be with Docparser.


