

How to Extract Text from a PDF with Docparser
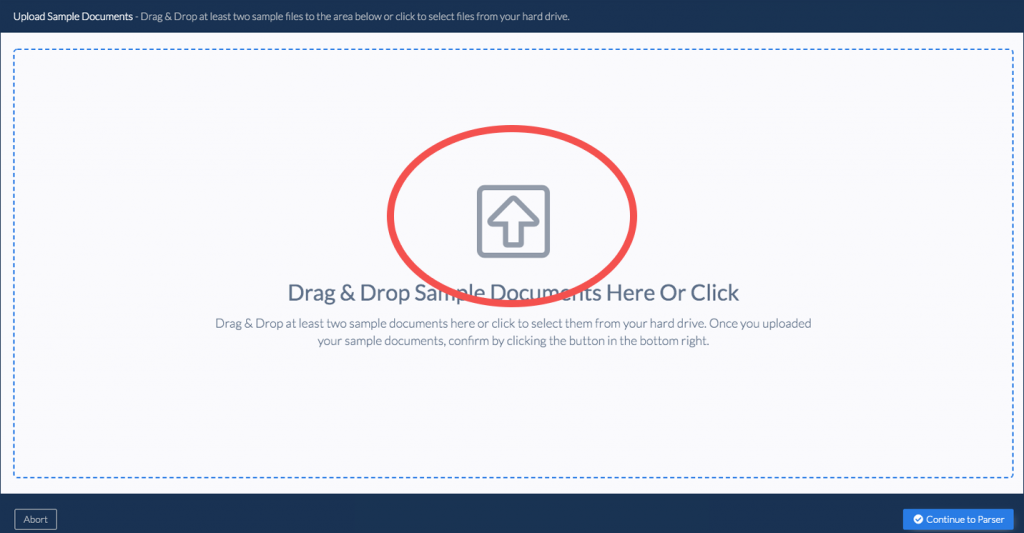
Step 1: Upload the PDF
Login to our OCR tool and select a PDF file to upload. You can automate this process, or upload one document at a time.
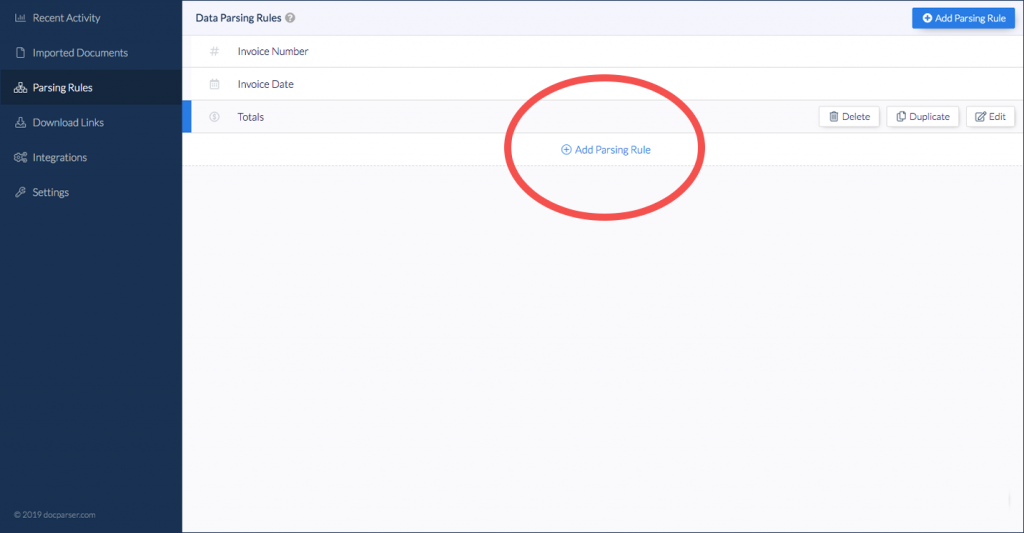
Step 2: Add Parsing Rules
Before separating text from the PDF, add rules to automate and speed up the process. That way, our system will know how to handle things like emails and phone numbers.
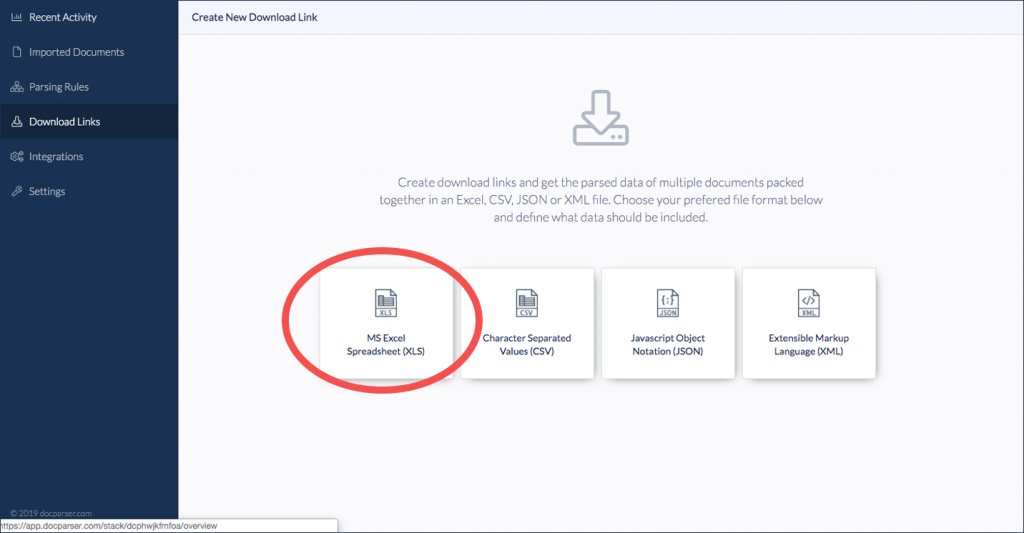
Step 3: Export and Save Your Text.
That’s pretty much it. Our app extracts your text right off the image or PDF for you to use as you desire. We even structure it for you as your rules require.

Who can benefit from OCR technology?

Any company of any size can leverage OCR data entry. As we’ve reviewed, OCR can be used to transfer immutable paper documents into editable ones. In addition, documents can be transferred to computers, smartphones, tablets, and other electronic devices.
Nearly any enterprise benefits from OCR technology but especially:
- Banks and other financial institutions
- Any customer-focused company
- Libraries
- Schools
- Medical practitioners
- And others
Some documents that are the best candidates for digitalization include:
- Invoices
- Research articles
- Tax documents
- Payroll information
- Contact information
- Customer data
- Legal filings
- Financial investments
- Among others
Examples of situations where you can use OCR technology:
Let’s say you’re on the road and pull out your cellphone to scan a client document.
Or your team has a data dump. You want to analyze data that matters.
Or perhaps a customer sends in a scanned copy of an invoice in JPEG form instead of PDF.
Or maybe your business needs to digitize records.
Whatever the use, OCR technology makes it all possible.
How can OCR software help me?

OCR technology has a variety of benefits. It allows you to:
Searchable Text for PDFs
OCR converts immutable text in PDFs into searchable and editable text, making search faster and more efficient. Say goodbye to sifting through pages of unsearchable documents and easily find the information you need.Simplified Editing with
OCR Make changes to your documents without the hassle of copy-pasting and composing new ones. OCR technology allows you to edit PDFs easily and quickly, making your documents adaptable to changes in your business.Error Prevention with OCR
Human errors are unavoidable, but OCR technology can help detect mistakes in your documents and resolve them quickly, ensuring accuracy and reliability.Time and Cost Savings with OCR
Reduce paperwork and manual data entry with OCR, saving time and money. Scan printed documents containing text and digitize them using OCR, eliminating the need for tedious data entry.Efficient Use of Office Space
Digitized documents take up no physical space in your office, allowing you to free up valuable real estate for other purposes. Store invoices, receipts, and other documents digitally, keeping your office organized and clutter-free.Increased Productivity with OCR
OCR enables faster data retrieval, making documents searchable, editable, and easily accessible. No more wasting time searching through file cabinets – your employees can focus on other productive tasks.Enhanced Data Security with OCR
Digitized documents are less prone to loss or damage compared to paper documents. OCR technology allows you to minimize access to files and protect sensitive information from mishandling or unauthorized access.Improved Customer Service with OCR
Quick data accessibility is crucial for businesses relying on customer information. OCR speeds up document retrieval, reducing waiting times and improving customer satisfaction, leading to better customer retention and future conversions.Disaster Recovery and Data Redundancy
OCR ensures that digitized documents are securely stored, making disaster recovery and data redundancy easier. Back up your documents to multiple servers in different locations for added protection against natural disasters or other unforeseen events.Simplified Document Upload with OCR
OCR, including Zonal OCR, allows for easy extraction of text from specific locations in scanned documents. Docparser, in particular, offers batch uploading of documents through various methods, such as drag-and-drop, API, or cloud integrations, simplifying the document upload process.
Docparser, in particular, lets you batch-upload your documents. You can drag and drop your documents from your local disk, or you can use our API or cloud integrations to import important documents automatically.
What type of text can you extract from PDFs?
- Invoices
- Purchase Orders
- Application Forms
- Standardized Contracts
- Shipping Orders
- Delivery Notes
- Work Orders
- Generated Report
- Bank Statements
- Fillable PDF Form
Docparser makes it not just easy and convenient to extract data from PDF, it can also make it programmed and automatic. In addition, it can also extract text from PDFs using a command line.
Once you upload your document, you can extract text from PDFs to convert PDFs to Spreadsheets, MS Word, JSON, XML, and CSV files.
Our superb parsing engine comes packed with parsing presets that can be customized as per your business requirements. For example, if your PDF contains tabular or graphic data, use our parsing engine. Once you have set up your parsing rules, Docparser will take care of the rest. It remembers your settings for the same type of documents and files, so you don’t have to set it up over and over again.
Suppose you have a batch of files from which you need to extract text–no worries! You can also upload the collection of files and process them simultaneously, thus saving you time and effort.
Docparser can also be integrated with 100s of apps at the front end or back end of your business workflow. These integrations make your data extraction process automatic. You can import documents using the integrations and extract text from them, or you can extract the data and get it exported in any app or format that you like.
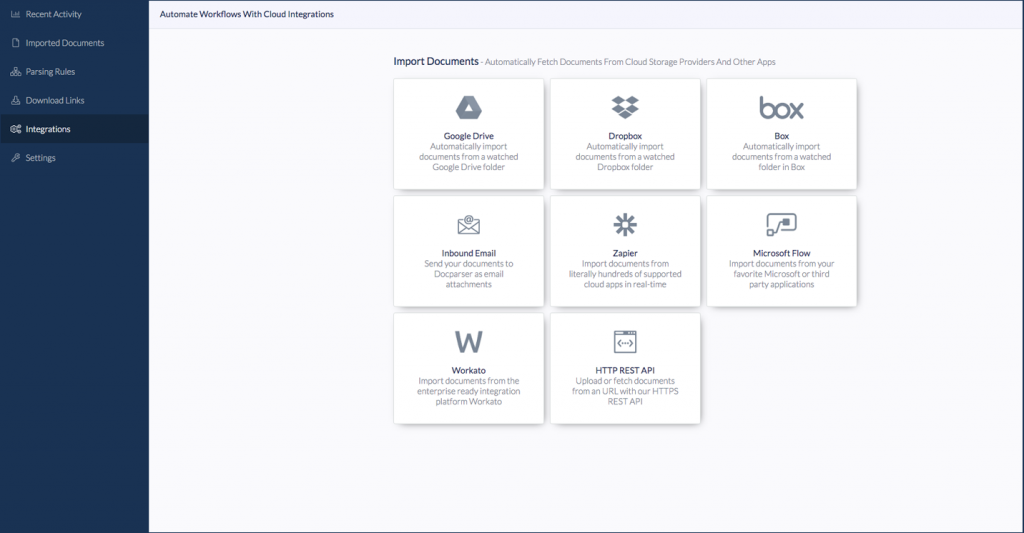
All in all, if your business deals with a vast amount of PDFs – of any type i.e., images, scanned files, you can safely and securely use Docparser to automate your business workflow. Once set up, data extraction from the PDFs works automatically without any manual intervention.


